A Labnaf White Paper
by Alain De Preter
Why do you need a (smart) architecture repository?
Why is this crucial for effective enterprise transformations?
An enterprise transformation framework is a framework that orchestrates all architecture and strategy disciplines needed to drive enterprise transformations.
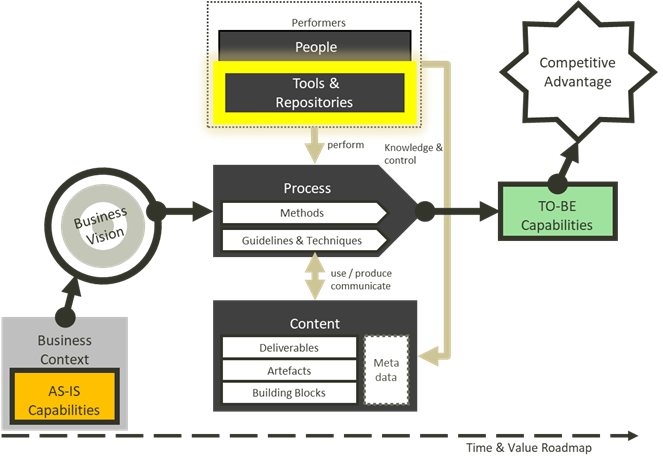
The enterprise transformation framework components are:
- the content,
- the process of driving transformations,
- the people,
- the tools and repositories (databases).
This paper discusses requirements to make a valuable architecture repository.
More about the scope of this paper
For the sake of readability, we will just talk about an “architecture repository”, though it also includes much strategy contents.
Other repositories, for example IT Finance, or the repository collecting incidents, provide input to the architecture repository. But these are not the purpose of this paper.
The Purpose of an Architecture Repository
A well-documented process for driving enterprise transformation tells you which kinds of strategy and architecture information will need to be managed in an architecture repository. The process tells you when this information is needed, and for which types of transformation decisions and outcomes.
An architecture repository is a vehicle used to classify, enrich, consolidate, store, secure, share and re-use this strategy and architecture information throughout the transformation process.
So, beyond the obvious read and write capabilities, the architecture repository must align to a defined transformation process. And to be effective,the repository must be unique, meaningful, well-structured with multiple levels of detail. It should support complex organizations when applicable. And it must be secure, automated, and well governed.
Let’s dive into these architecture repository requirements one by one.
Align to a defined Transformation Process
An architecture repository structure should serve as an assistant to users who organize, store, search, share and secure the strategy and architecture content created throughout a transformation process.
Each type of content created during this process needs a dedicated location in the repository.
And it is easier for stakeholders to find content when the structure of the process and the structure of the repository share a similar terminology.
As an example, lets’ see, overall, how strategy and architecture content gets created and reused throughout the Labnaf process of driving transformation.During the process, this content needs to be stored and retrieved from the architecture repository.
The Labnaf process for driving transformation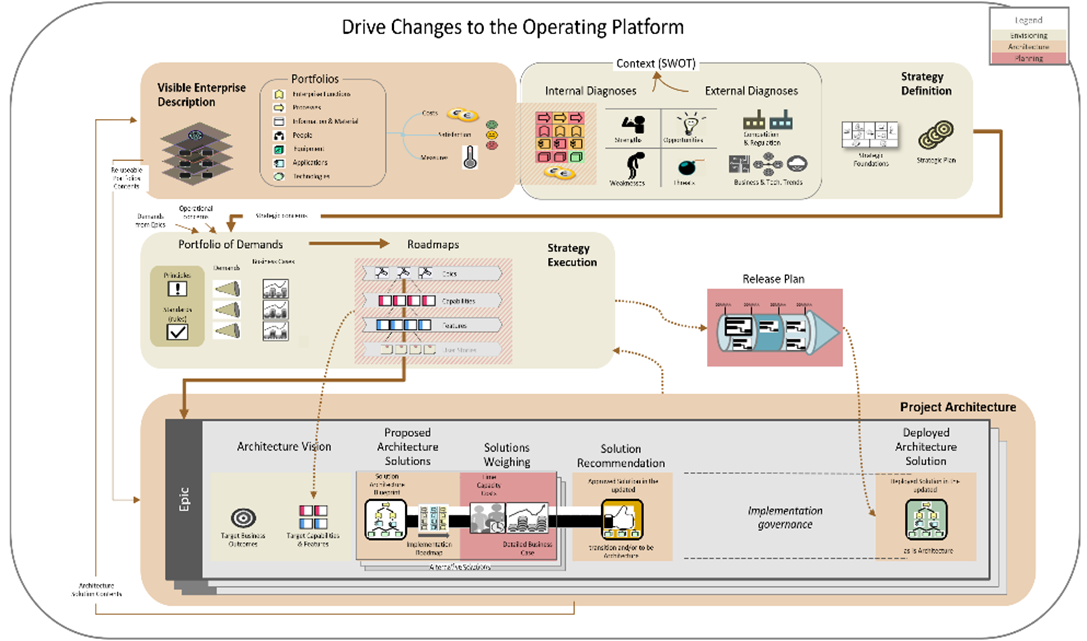
During this process, you first describe, visualize and diagnose the enterprise, how is it working, what is the operating model, and where are the challenges.
By having a clear view on the business context, you can then define a meaningful vision, a strategy for the future. And to execute this strategy, you create roadmaps, you define steps to get where you want to be.
These roadmaps contain the target capabilities that you want to deliver.
In Labnaf, epics are architecture endeavors delivering target capabilities descriptions in the form of architecture solutions. These architecture solutions reuse, enrich, and update the enterprise description.
For those familiar with IT4IT, the Labnaf process of driving transformation corresponds to the first step in the IT Value Chain.
The following picture illustrates how the repository structure maps to the process.
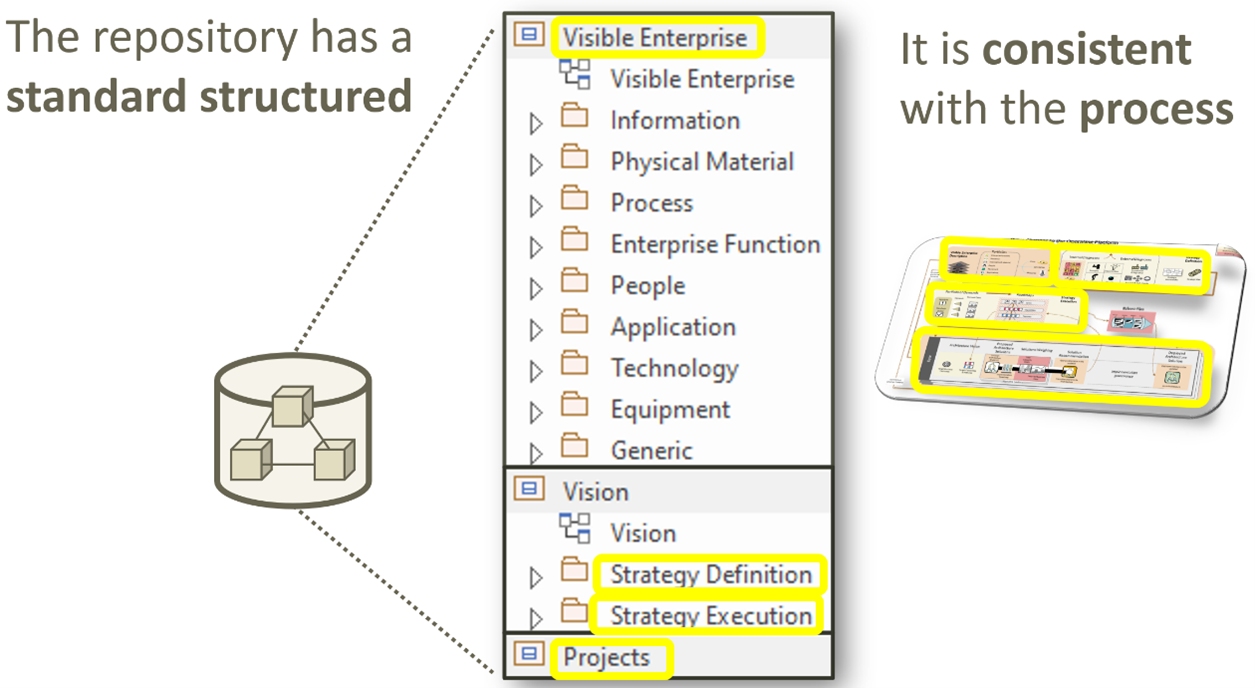
Unique
Your architecture repository must be unique.
And for effective collaboration, the unique repository should integrate with a single, process, modeling language and software environment covering enterprise architecture, strategy and solution architecture.
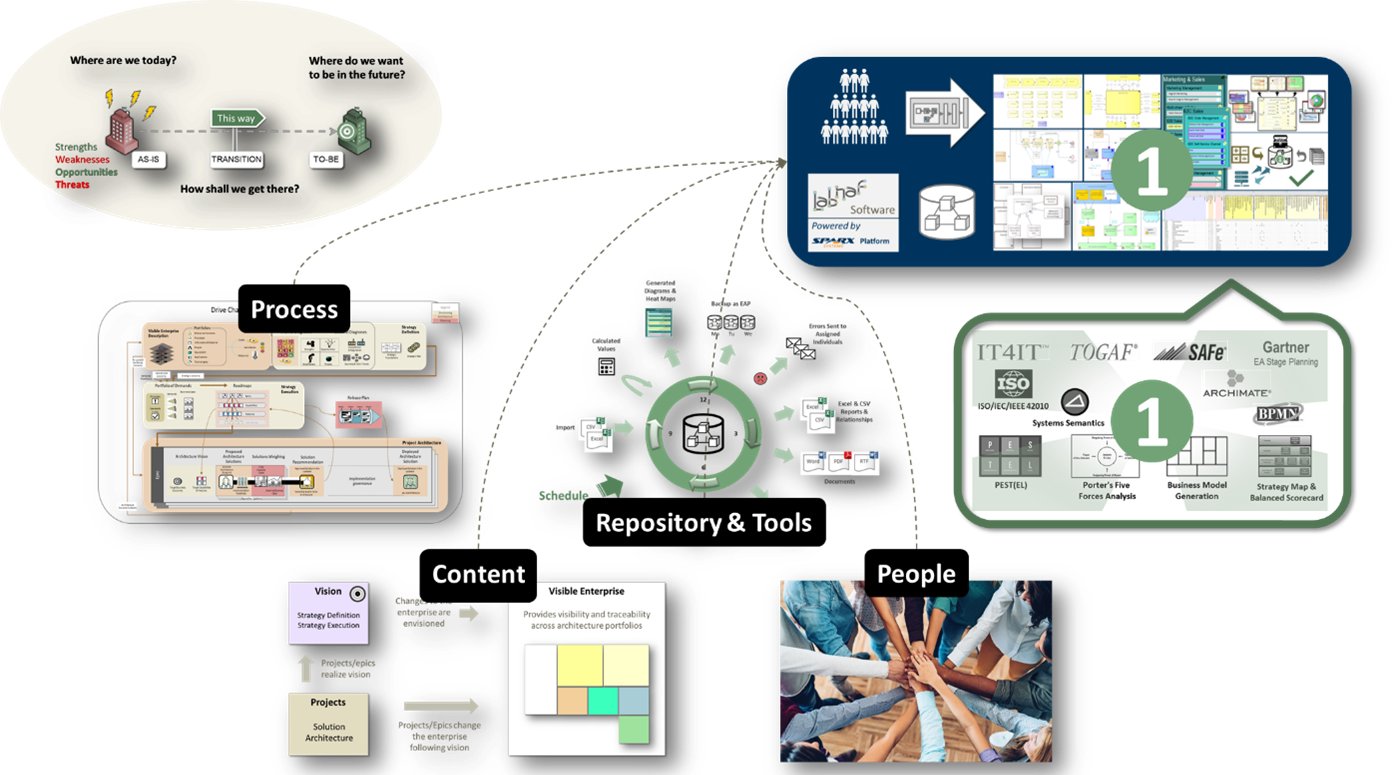
The Labnaf framework components
Why is it a problem of having multiple architecture repositories?
Many organizations and departments use a combination of architecture repositories (and also multiple modeling languages, processes, standards, and tools). This generates large amounts of incompatible or redundant puzzle pieces that jeopardize collaboration. This in turns leads to inadequate transformation decisions and architecture solution which in turn lead to technical debts and missed opportunities.
Meaningful and Well Structured
To be understandable, scalable, and to ease content enrichment, your repository organization must be clear, intuitive, and precise. Same for the related language and metamodel.
An enterprise is a system. Every thing in the universe is a system. An enterprise is therefore better modeled using the natural concepts of a system.
Example: To describe an enterprise, Labnaf organizes architecture following generic systems semantics (it also uses this to semantically merge numerous standards). The following picture provides a high-level overview of some related concepts that are used to define and relate architecture portfolios in the repository.
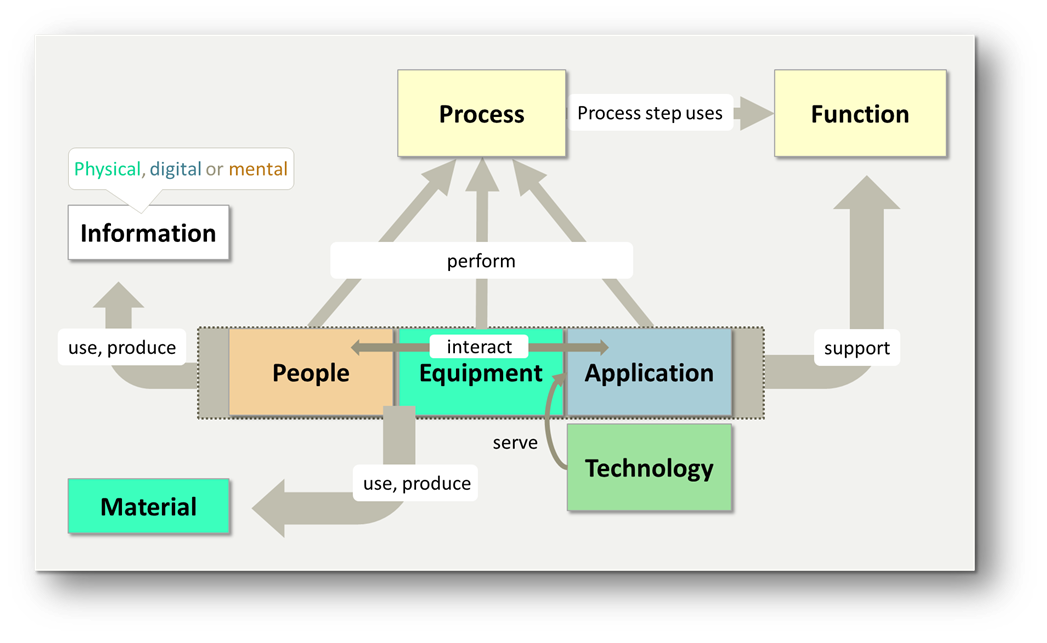
For further information, you might watch this video
For comparison, the next picture describes a bizarre “markitecture” approach for organizing architecture content. Many organizations use a similar repository structure which we find unintuitive and unnecessarily complex.

Multiple Levels of Detail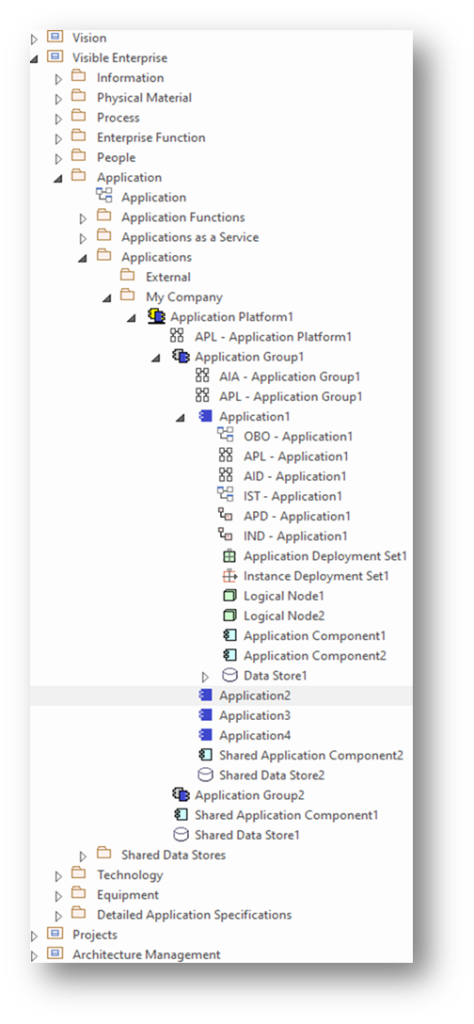
The repository, the modeling language and the metamodel must assimilate elements of various levels of architecture details depending on the audience and needs.
Enterprise architects, for example, manage the application portfolio using coarse grained elements. These elements could be enterprise functions (aka ‘business capabilities’) like ‘Sales’, with their supporting application e.g. ‘SAP CRM’. These applications might be organized into application groups, like SAP Business Suite’, and application platforms, like ‘SAP Platform’.
Solution Architects, on the other hand, typically dives into details, including application components, data stores, and deployment specifications. So, carrying on with the same example, solution architects could define a SAPR CRM server and a SAP CRM data store.

Support Complex Organizations
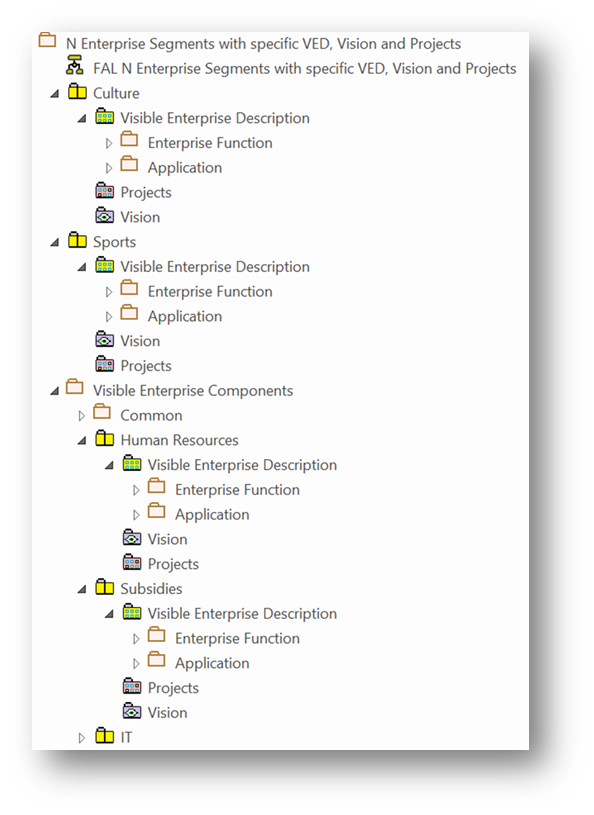
In the following repository excerpt, each public organization (Culture, Sports …) has its own specific enterprise description. These public organizations share some components including enterprise functions and applications.
The repository and the modeling language need to support complex organizations with multiple segments.
Secure
The more complex the organization, the more security requirements arise.
Users of the repository need to be authenticated using SSO.
And stakeholders will typically want to restrict access to certain areas of your repository. For example, the above Subsidies and HR architecture segments might be visible only to some audiences, while the Sports segment might be changed only by architects that belong to the Sports organization.
Click on this link to get further information about the implementation in Sparx-Labnaf
Automated
A smart repository performs data enrichment and distribution operations.
The consolidated or unconsolidated data can then be presented to the different audiences in the form of dashboards and reports.
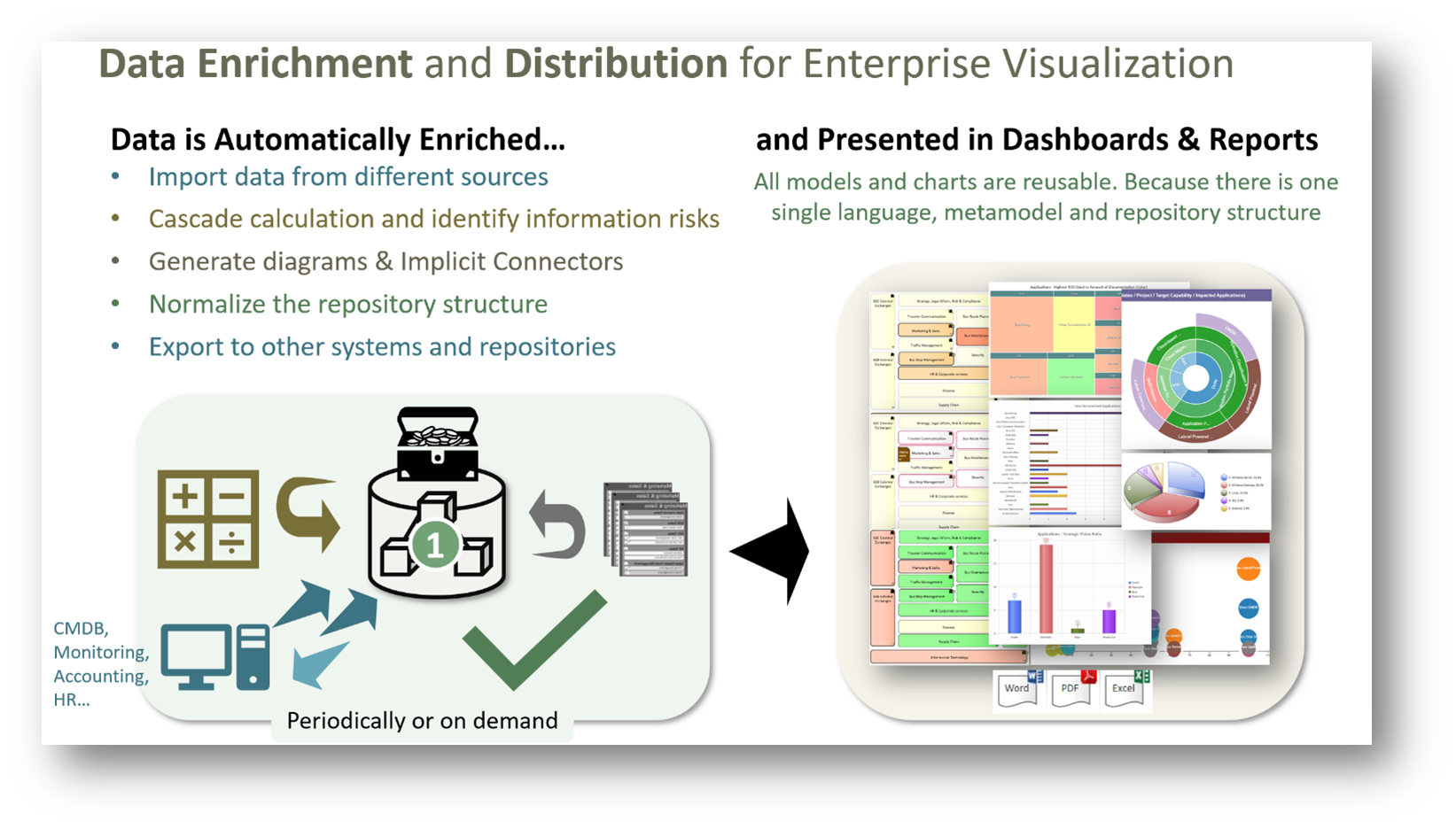 Data enrichment includes external data import, cascaded connector generation, cascaded calculations, resource usage and risk identification, diagram generation, and automatic normalization of the repository structure.
Data enrichment includes external data import, cascaded connector generation, cascaded calculations, resource usage and risk identification, diagram generation, and automatic normalization of the repository structure.
The smart repository performs technical validation of its content, as described in next section. It also synchronizes its content with external databases i.e. with other systems.
Automated operations can be both scheduled and triggered by end users on demand.
Well governed
A well governed repository requires regular business and technical validations.
Business validation is performed by people who compare, for example, the value of some proposed strategy, some target capability planning, or some architecture solution against stakeholders’ requirements and constraints.
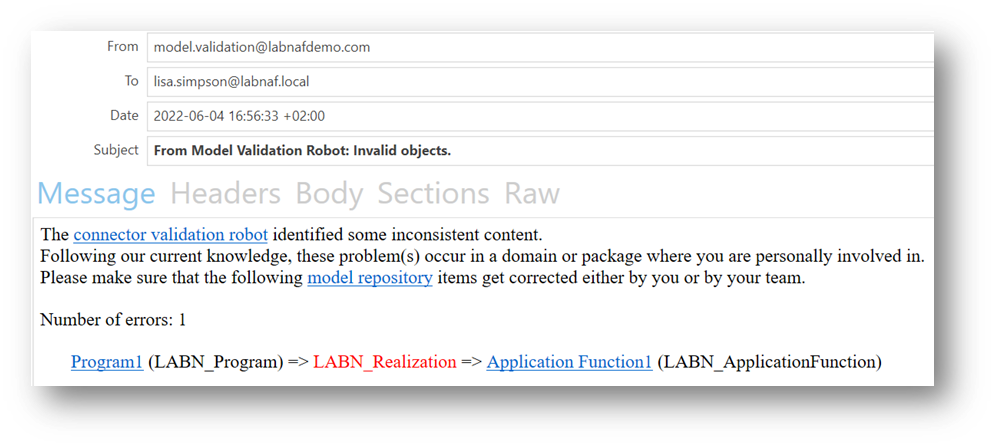
Technical validation can be mostly automated.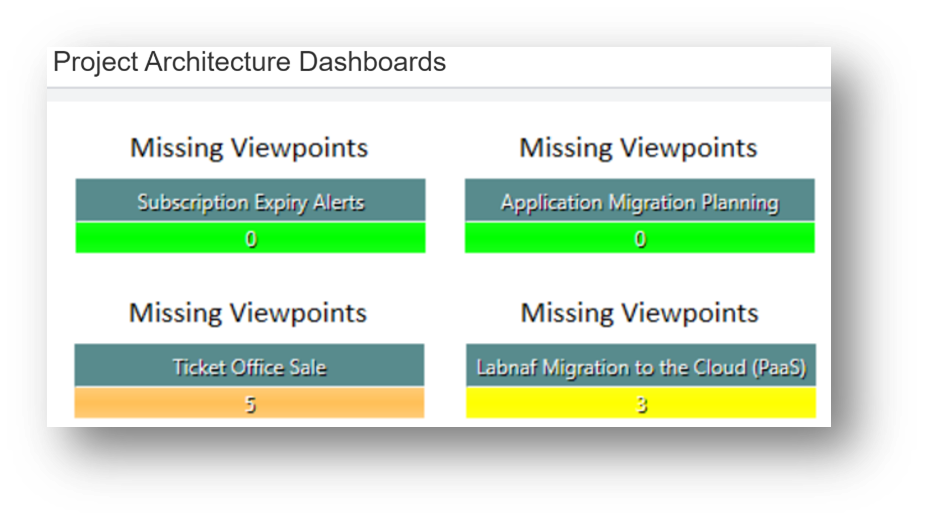
The typical items that need to be technically validated are:
- the list of delivered views/diagrams and documents against the list of mandatory views and documents for each specific type of project
- the element connections against the metamodel
- the repository folder and element structure
- individual element property values
- the consistency between related property values
Whether it is automated or not, the typical validation steps are:
- Review
- Problem identification
- Identification of implicitly or explicitly assigned individuals
- Explaining/sending notification to the assigned individuals
- Fixing the problems
About the author
Alain De Preter is a Belgian expert developing architecture frameworks, modeling languages and software technologies. He has more than 35 years of international experience in innovation projects leading to large-scale deployments. Alain founded Labnaf in 2019.






