Nobody can deny that artificial intelligence (or machine learning, deep learning, or cognitive computing) is booming these days. And — as before, as this is in fact the second round for AI — the hype is almost unlimited. But there are serious problems, and I suspect it will not be long before they become undeniable again and we’re back to a more realistic assessment of what the technology is bringing us.
There are roughly four types of problems in the land of AI. Let’s start with an illustration of one of these, where the hype doesn’t live up to reality yet and where it is quite possible that it never will.
Gorillas
In 2015, Google had to apologize because its analytics software tagged a picture of two black people as gorillas. Google’s chief architect at the time wrote: “We used to have a problem with people (of all races) being tagged as dogs, for similar reasons. We’re also working on longer-term fixes around both linguistics (words to be careful about in photos of people) and image recognition itself (e.g., better recognition of dark-skinned faces). Lots of work being done and lots still to be done, but we’re very much on it.” Fast-forward three years and it turns out what Google’s quick and dirty linguistic fix was to: ban the word “gorilla” altogether. This is very indicative of a fundamental problem: In three years’ time it was not able to fix the issue. Banning the word “gorilla” altogether is not a fix, it is an admission of failure.
And here is a sign that we’re still deep in hype mode: when reporting on this, the Guardian writes: “The failure of the company to develop a more sustainable fix in the following two years highlights the extent to which machine learning technology, which underpins the image recognition feature, is still maturing” (italics mine). This is a sign of hype as it assumes (without reasonable proof) that the problem is solvable at all. And it is by definition limited in time, as you cannot keep writing that something is ‘maturing’ for extended periods of time.
These kinds of problems (and this kind of reporting in the press fully mirrors what happened in the 1960s and 1970s. Many reported successes weren’t real and the failures were either painted over, not reported, or labelled “still maturing,” implying: there is nothing wrong with the approach itself. I already noticed the same vein in reporting in journals like the New Scientist already years ago. Good examples were articles listed “the X most interesting scientific and technological breakthroughs.” Such lists generally contained at least one AI-like item and such an item was often also the only item that wasn’t reality yet. Often (just as in the first AI hype period) these were reported as failures “that just needed to mature,” “fix a few outstanding issues,” etc. All the others in the list were proven breakthroughs (e.g., a mechanism that worked, even in volume, but only was too expensive yet to produce in volume), but the AI ones were always only breakthroughs if we assumed totally unfounded extrapolations. There is a disturbing lack of criticism when AI is being reported upon. By the way, I like New Scientist a lot. This just shows that even serious science journalism is not immune to the hype.
For those experienced enough (a nice way of saying “old buggers”) to have been on the inside of the first period of AI hype (1960 to 1990), the current hype shows some distressing parallels with the previous one, in which hundreds of billions were spent in vain to get the promised “artificial intelligence.” In 1972, from Hubert Dreyfus’s book What Computers Can’t Do, it was already clear the approaches were doomed. It is a testament to the strength of (mistaken) conviction that was behind the first AI hype that it took another 20 years and billions of dollars, spent by governments (mainly in the US, the EU, and Japan) and private companies (Bill Gates’s Microsoft was a big believer for instance) for the AI hype to peter out and the “winter of AI” to set in.
Did that mean AI failed completely in the previous century? Not completely, but what definitely did fail was the initial wave and the initial assumptions on which it was built. This current AI hype is seemingly built on different assumptions, so theoretically it might succeed. The question then becomes “Are we closing in on the goal this time?” The answer is again no, for some fundamental reasons I mention below, but the situation is also different and more actual value results from the current efforts.
Great expectations and failure, round 1
With the early rise of computers in the 1950s and 1960s there followed a fast rise in the belief that these wonderful computers, that could calculate so much faster than any human could, would give rise to artificial (human-like) intelligence. Early pioneers wrote small scale programs that were able to first beat humans in tic-tac-toe, then checkers, and in 1970 we already read predictions that computers would be “as smart as humans in a matter of years” and “much smarter a few months later.” Within ten years the world chess champion would be beaten by a computer.
Computers as intelligent as humans (even if specialist programs eventually could outcalculate human intelligence in microworlds such as chess) failed to materialize decade after decade, until in the 1980s the “winter of AI” slowly set in. I often lament the billions Bill Gates’s Microsoft poured into AI (in which he believed strongly) to produce duds like Microsoft Bob, Microsoft Agent, the infamous Clippy, and lots of vaporware, where it could have fixed its software to be less of a security nightmare and actually work decently (e.g., it is moronic that even in Windows 10 today, if you share a spreadsheet from within Excel, which creates a mail message in Outlook, Outlook is incapable to do anything else until the window containing the spreadsheet to be sent has been closed. Something NeXTStep, now macOS, could already do 25 years ago, but I digress).
But the whole subject in the end came to nothing. Expert systems turned out to be costly to build and maintain and very, very brittle. Machine language translation based on grammars (rules) and dictionaries never amounted to much. The actual successes often had one thing in common: they restricted the problem to solve to something computers could manage, a microworld. For instance, using a small subset of English (e.g., Simplified Technical English). Or, using the fact that the possible existing combinations of street names, numbers, postal codes, and city names gave such a good limitation of the search space that mail-sorting machines could get by with a measly 70 percent accuracy of actually reading the addresses themselves. It is how a system like Siri still works (poorly, as far as my experience goes) today: it is limited to a small set of ‘microworlds’ in which it can try to create a structure from sounds (which is a far cry from an actual natural language interface).
As mentioned above, the failure was already predicted in the late 1960s by Dreyfus, who — after studying the approaches and ideas of the cognitive science and AI communities — noticed that their approaches were based on misunderstandings already known from analytic philosophy, which had hit those same limitations before. But who listens to philosophers, even if they are of the analytic kind?
Anyway, in 1979, the second revised edition of Dreyfus’s seminal book was published. It showed, that much of the additionally reported progress was again illusory and it analyzed why. And finally, in 1992 the third and definitive edition was published by MIT Press (MIT being a hotbed of anti-Dreyfus sentiment in the years before). Twenty years in a field supposedly developing with a speed beyond everything that went before, with computers that had become many orders of magnitude more powerful, but the book remained correct, and in fact is correct (and worthwhile to read) to this day.
In the 1992 edition, Dreyfus described an early failure of the then-nascent “neural networks” approach (the approach that underlies many of today’s successes, such as Google beating the human Go champion). The U.S. Department of Defense had commissioned a program that would — based on neural network technology — be able to detect tanks in a forest based on photos. The researchers built the program and fed it with the first batch of a set of photos that showed the same location, but one with a tank and one without. After having trained the neural network thus, the program was able to detect tanks with an uncanny precision on photos from the training batch itself. Even more impressive, when they used the rest of the set (the photos that had not been used to train the neural network), the program did extremely well and the Department of Defense was much impressed. Too soon, though. The researchers went back to the forest to take more pictures and were surprised to find that the neural network was not capable of discriminating between pictures with and without tanks at all. An investigation provided the answer: It took time to put tanks in place or remove them.
As a result, the original photos with tanks had been made on a cloudy day, the photos without tanks had been made on a sunny day. The network had effectively been trained to discriminate between a sunny (sharp shadows) and a cloudy day (hardly shadows). Fast-forward thirty (!) years and the deep learning neural networks or equivalents from Google run into exactly the same problem. Their neural networks have learned to discriminate, but not enough to discriminate between black people and gorillas, and it is actually not very clear what they discriminate on.
And yes, Google can now beat the best people at Go, which is much more difficult than chess (where IBM beat the best people in the 1990s), but Go and Chess are still examples of the microworlds of the late 1960s. Even more important: these are strictly logical (discrete) microworlds, and people are extremely bad at (discrete) logic. We might be better at it than any other living thing on this planet, but we’re still much better at Frisbee. (This by the way is one of the reasons why rule-based approaches for enterprise/IT architecture fare so poorly: The world in which enterprises/computers must act is not logical at all.)
Great expectations, round 2. Failure ahead?
Neural networks and other forms of statistics require lots of data and “deep” (i.e., many-layered) networks to amount to anything. In the 1960s and 1970s the computers were puny and the data sets were tiny. So, generally, the “intelligence” was based on direct creation of symbolic rules in expert systems without a need for statistics on data. These rule-based systems (sometimes disguised as data-driven — such as the Cyc project which stubbornly plods along with the goal of modeling all facts and thus come to intelligence — failed outside of a few microworlds. Cyc, by the way, is proving that even with a million facts and rules, you still have nothing that looks like true intelligence.
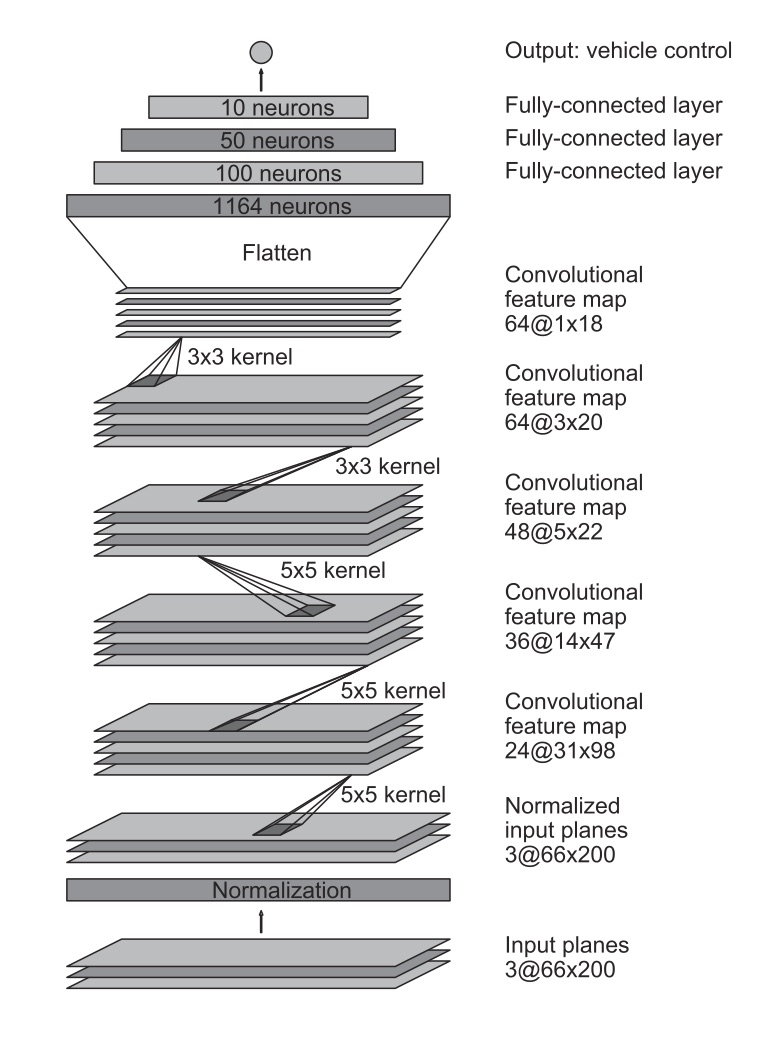
Anyway, the first neural networks were “thin,” initially two, maybe three layers to create the correlations between input (e.g., photo) and output (“Tank!”). Such thin networks are very brittle. With more “depth” today, they have more hidden rules (e.g. have a look at this Nvidia study on a 9-layer, 27 million connection, 250 thousand ‘parameter’, neural network for a self-driving car). The statistical correlations are still equivalent to rules, these days deeper than mistaking a sunny day versus a cloudy day for “tank” versus “no tank.” In fact, while we do not know the actual rules, the neural networks on digital computers are still data-driven, rule-based systems in disguise. Smart “psychometrics” systems may still contain meaningless relations like between liking “I hate Israel” on Facebook with a tendency to like Nike shoes and Kit Kat.
Now, over the last decade, the amount of data that is available has become huge (or, at least according to our current view, don’t forget that researchers in the 1960s already talked about the issues that came with trying to program the “very powerful” computers of the day). This has opened up a new resource — data, in this light sometimes called the new “oil” — that can be exploited with statistics. To us, logically woefully underpowered humans, it looks like magic and intelligence. These statistical tricks can draw reliable conclusions that are impossible for us to draw, if alone because we as human beings are unable to process all that data and calculate those statistics without the help of computers.
But look a bit deeper, and you will often still find shockingly simple rules that are in fact unearthed and used. One specialist told me: Most of the time, when we do statistical research on the data, we find correlations around some 14 different aspects: ZIP code, age, sex, income, education, etc. And these predict with a decent enough reliability how we should approach customers (and they often work as useful proxies, but that comes with risks, see below).
The patterns (rules) unearthed are thus rather simple and have two important properties:
- They are not perfectly reliable. They all come with a percentage of reliability, as in “90 percent reliable correlation.” That means in many cases they produce erroneous results.
- The more restricted the range of predictions, the more reliable they are.
So, how bad is it that these methods have reliability issues? Will this statistics-based AI fail as spectacularly as the earlier symbolic wave did? The answer is no. If you can support your customer with a method nine out of ten times well, that is a good thing, right? Unless, of course, the remaining 10 percent are making so much fuss in social media that your brand suffers (“Google labeled me a gorilla!”). At this stage in the game, nobody pays much attention to the outliers, and that is a recipe for disaster.
Remember the financial crisis? You know what a big part of its origin was? Statistics. The quants of the financial sectors had created statistical models that gave their users the illusion that they had done away with uncertainty. Their spreadsheets with formulas (1960s computer intelligence) and Monte Carlo simulations (1980s computer intelligence) broke down because of the outliers, unleashing the biggest economic crisis since the 1930s. Given the naivete of many current initiatives, it’s just a matter of time of something likewise happening in the new big data space.
But sometimes it is enough for statistical methods to have very small effects to be useful. So, say you want to influence the US elections. You do not need to convince everybody of your message (fake or not). You maybe can swing an election a very worthwhile 0.2 percent by sending negative messages about a candidate to a selected group of his or her supporters. Suppose you can target a specific 22 percent, say black people who support your opponent for 90 percent. You get 50 percent of them to see a message that puts the candidate in a racist or antiblack context. If this suppresses the turnout of 80 percent of those that saw the message by 10 percent while (out of anger because the message is so unfair) it increases the turnout of 5 percent of that same group by 60 percent (they are reallyangry about the unfairness of the message), then you have just created a 0.2 percent lower poll result for your opponent. A couple of such differences may win you elections. This is not farfetched. Such weaponized information has been used in the US 2016 election and in the Brexit referendum, where very small effects like these have apparently had a big effect on the outcome. It gets even better the more “micro” the targeting becomes.
That information can sway voters is a given. But, as one of the major players stated: it does not have to be true, it just has to be believed. This is supported by evidence: a recent study from Ohio State University suggests (not proves) that believing fake news may have influenced the outcome of the US 2016 presidential election by influencing defection by voters. So, the combination of statistics on large data sets and fake news is a ‘weapon’ in the the age of information warfare we now find ourselves in. And we, the population, are the target. We, the population, have been lured by “free” and addictive products like Facebook, and we, the population, have been not only been set up as a resource to be bought and sold (not physically, but mentally) and set up as the instruments by which information warfare is fought. So, how does it feel to be a means to somebody else’s end? Nobody is aware, so nobody cares.
That suggests that something is different this time. Apparently, the law of large numbers makes it possible for even statistically small or not very reliable technology to have a deciding influence. The first wave of AI was largely ineffective. This new wave actually does have a very big effect on societies. This is especially true in situations of near equilibrium (such as hard-fought elections) where small changes may have huge effects or in situations where false positives or false negatives are not very damaging. District-based democracies may be more vulnerable because of their winner-takes-all setup, but equal representation democracies are not immune. In other words: Our statistics-based methods work very well where small changes in averages are the goal. If you want to improve revenue by a few percent, using methods that may alienate a small part of the population but endear a larger part is a good thing — as long as the negative side doesn’t blow up in your face.
Which brings us to some actual limitations I’d like to draw your attention to.
A shortlist of limitations
Fundamental limitations of statistics-based technologies are:
- Errors in singulars. Statistical methods are not perfect. We saw this already in the gorilla example, but the best example may be Google Translate. It is OK, but it is far from something that is reliable. Most of the time it needs quite a bit of human intelligence to guess what has been said. Small errors can have too much of a devastating effect for it to become as good as it need be. So, on average the technology does something useful, but for the individual user it cannot be relied on. This means that when you are thinking about the role of statistical methods for your organization, you need to stay away from anything where the answer for the user must be precise. Advice with legal ramifications (e.g., if you give financial advice and the law sets requirements on the care for the individual customer) is a good example where you need more than a chance of being correct to be useful.
- Unwanted prejudice. Neural networks (deep or otherwise) and mathematically equivalent techniques link inputs and outputs, but you do not know how. So, as with the tank example, while you think you are targeting richer people, you may be targeting whiter people. Although whiter people may on average be richer, it is still not ethically acceptable to target whiteness as a proxy for richness. Which, ironically, is why proxies are also often used where direct targeting is illegal or unethical. So, while proxies can work for you, unwanted proxies may work against you.
- Conservatism. Basing your decisions on data from the past turns you into a natural conservative. So, these technologies will fare poorer when change is in the air or when change is needed. This is a bit like Henry Ford’s old statement that if you would have asked the population about improving transportation they would have requested a faster horse, not a car.
- Spinning out of control. When I worked for BSO Language Technology in the early 1990s, the researchers had created a very simple statistics-based method that outperformed rule-based (in Lisp often) text indexing at a fraction of the fraction of the cost. It went in production at a Dutch national newspaper. The newspaper was so impressed that it wondered if it could fire its entire indexing staff, but we had to warn them. Small errors accumulate and can completely derail the reliability of these statistics-based systems. A good recent example was how Microsoft (really, it should put their efforts in fixing Windows) in March 2016 went live with Tay, a chatbot that was quickly subverted by its users to become a racist persona tweeting praise on Adolf Hitler and got shut down after 16 hours by Microsoft. A year later Microsoft was at it again with Tay’s successor Zo. Which was then caught making similar errors including stating that Windows 8 was spyware, that Windows 10 was no improvement over Windows 7, and that Windows XP was better than Windows 7.
So, where does that leave us?
Well, we can clearly see that the amount of data that is available makes more and more statistical methods effective. And it is growing exponentially, so we’ve seen nothing yet, including the interesting side effects this is having on IT infrastructure. Some label it “intelligent,” “deep learning,” or “cognitive computing,” but the fact remains that it is nothing more than (often pretty simple) statistics on huge data sets. It is not “intelligent,” nor does it really “learn”: the learning is just data-driven, hidden-rules computing, and Dreyfus’s critique that rules have little to do with intelligence still holds. And if someone comes by talking about cognitive computing, please do not listen; the use of such a term is a clear sign that he or she has no clue what he or she is talking about. Don’t forget, already in 1957 researchers produced programs they christened General Problem Solver while it definitely wasn’t a ‘general’ problem solver at all.
The most important lessons are:
- Statistics can be very effective and worthwhile; they’re not nonsense. But …
- Make sure your plans for analytics do not assume you can do singulars without people in control (analytics-assisted human activity, or AHA).
- Make sure your plans take the new brittleness of the “new AI” in account (again: You will need people).
- Make sure your new statistics-based operations are ethical.
- Make sure you plan for much more storage and compute power close to that storage.
- Ignore everyone who talks about “cognitive computing” or “the singularity,” and in general everyone who champions new technologies without understanding their limitations. These people are peddling General Problem Solvers, and they’re going to be very expensive to listen to.
Featured image: CNN Architecture from the mentioned Nvidia study End to End Learning for Self-Driving Cars.
This article first appeared in a slightly different form on InfoWorld.







Agree with the article. Intelligence can’t be artificial. 🙂
Thanks. The question becomes when is ‘artificial’ artificial? What does it mean? If you mean “we cannot build (human-like) intelligence” I disagree. In theory we could and this is proven by our own existence: we are biological ‘machines’ and we are ‘intelligent’ (though one wonders, sometimes…). It’s just not possible to build intelligence with digital methods, I think. Of course, we would be creating a new ‘species’ of which it would be likely we would be unable to understand its intelligence (as we do not share the same experience), so measuring it would be a challenge.