A while ago, a company I know got an offer from a vendor for a certain solution. The solution was a very specialised domain-specific application that ran on an operating system and used a database. About as simple and standard a stack as you can get.
What was special about the offer was their deployment approach. They did not offer an install package for the company to install on the company’s environment, no, their distribution was an image of a virtual machine, which in turn contained the application, the database, the operating system, and all the platforms (think Java etc.) required for running the whole shebang.
Such an offer presents the organisation with an interesting dilemma. Because organisations generally have standards in their environment. They support only operating systems X and Y, only Java versions such and so, only hypervisor P, and so forth. Organisations all use standardisation as an important instrument to fight diversity, because diversity is in many ways expensive. For each platform you need to have the knowledge, the support, the tools and so forth. It is way too costly to support everything. The financial squeeze that has been put on IT departments for a few decades has led to a common theme seen everywhere: a strict standardisation policy.
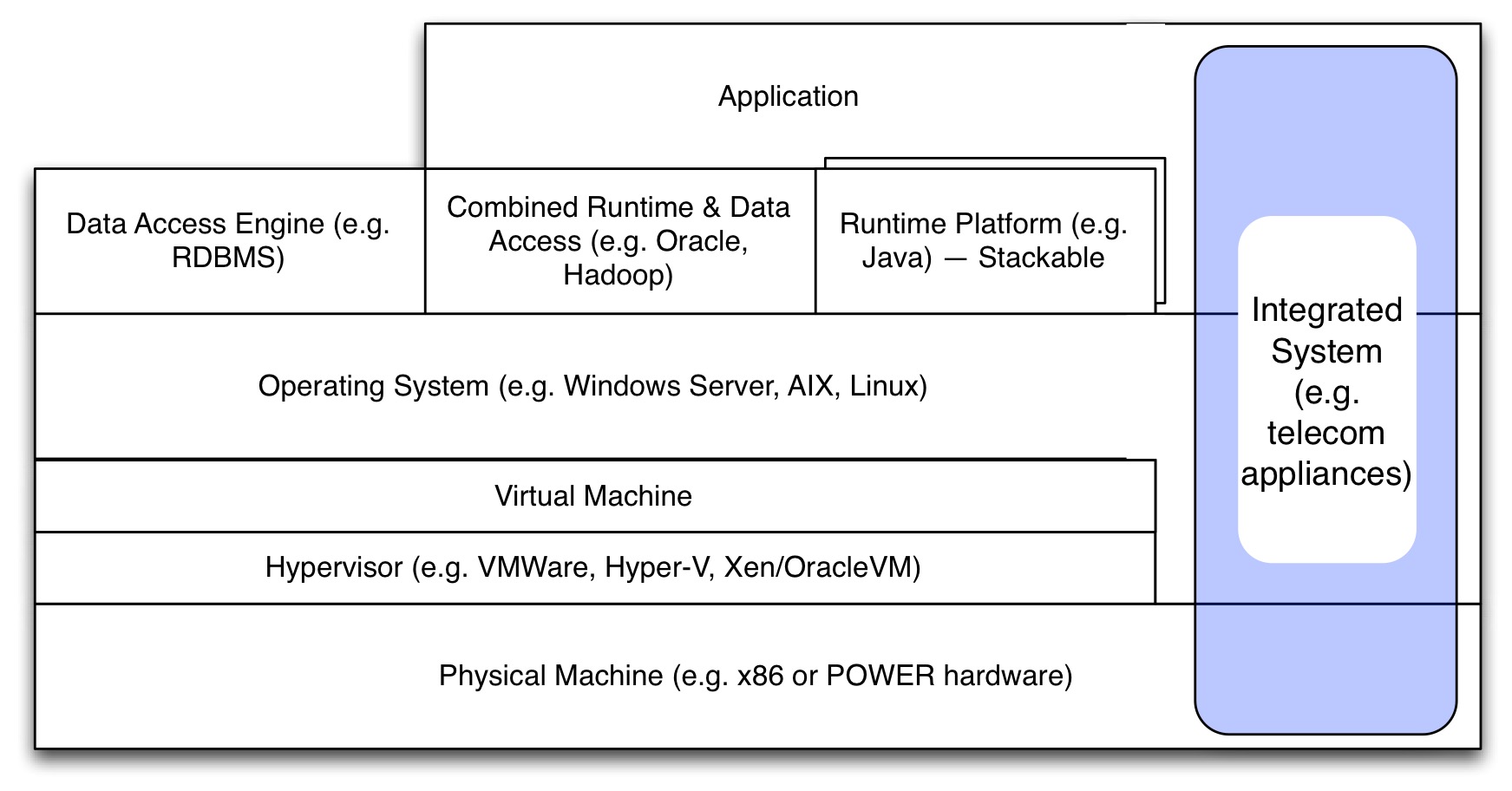
Generally, this policy is structured along a standard stack, of which a simplified version can be seen here:
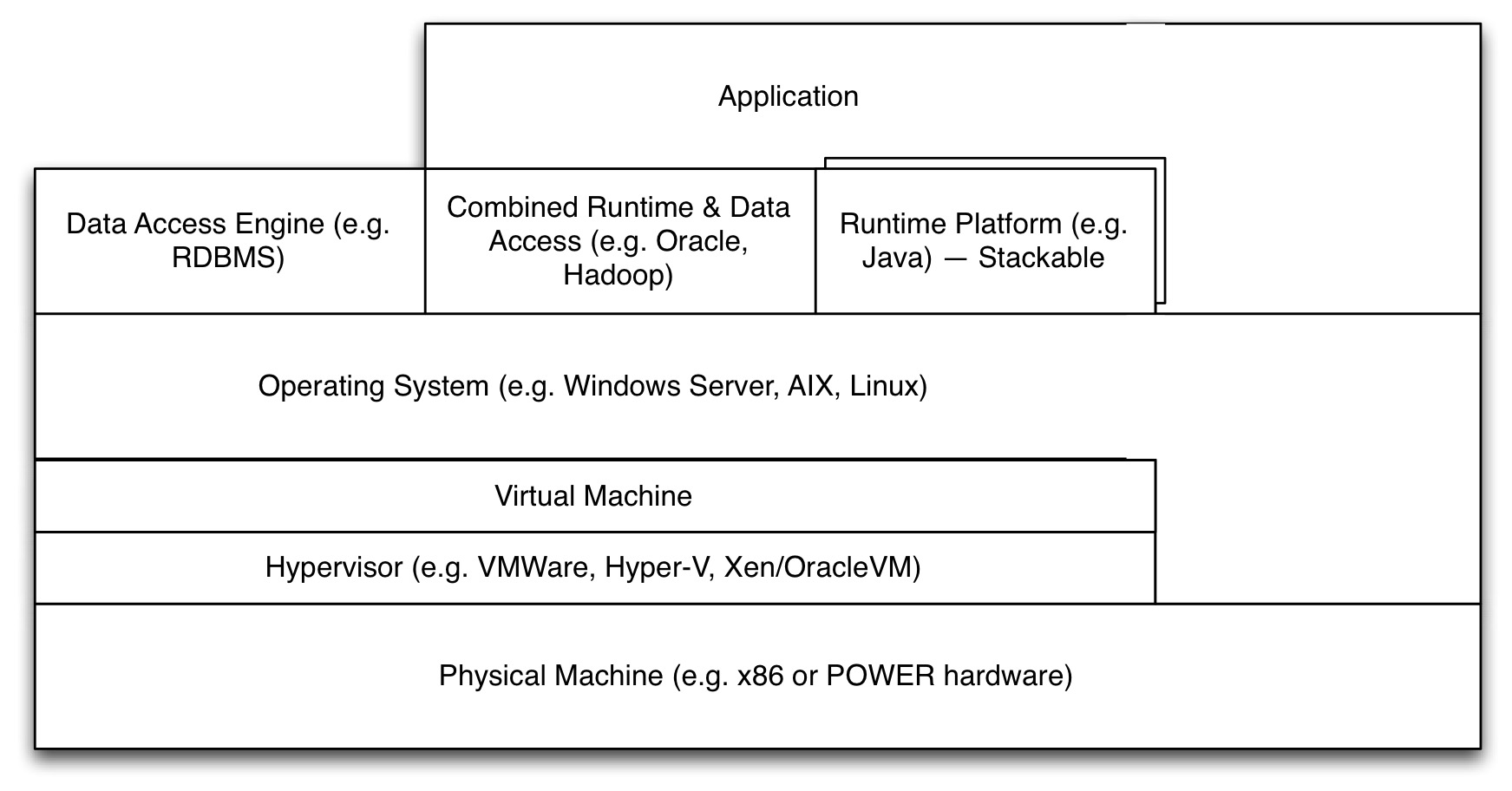 At the lowest level there is of course hardware, a computing device. On top of that, of old there would be an operating system (again, of old: the supervisor). These days, thanks to hardware virtualisation, a hypervisor runs on the hardware, which allows virtual machines to exist which, from the perspective of the operating system on top of it, are indistinguishable from real hardware. Not quite, but in most situations this is true. Virtualisation comes with big benefits, mainly in terms of resource utilisation and flexibility.
At the lowest level there is of course hardware, a computing device. On top of that, of old there would be an operating system (again, of old: the supervisor). These days, thanks to hardware virtualisation, a hypervisor runs on the hardware, which allows virtual machines to exist which, from the perspective of the operating system on top of it, are indistinguishable from real hardware. Not quite, but in most situations this is true. Virtualisation comes with big benefits, mainly in terms of resource utilisation and flexibility.
Whatever the ‘hard’-ware (physical or virtual), on top of it we find an operating system, such as Windows or Linux. And on that operating system various types of software can be installed. On a simple desktop, application may run directly on the operating system. But we can also install platforms (the operating system itself is a low-level platform) in which we can run other systems, which themselves can be platforms again. E.g. we can install a Java platform, then in that platform run a generic rule engine of some sort and load a set of rules in them that make up an application. The application runs on the rule-based engine, the rule-based engine runs on Java, Java runs on the operating system, the operating system runs on a virtual machine, which ‘runs on’ (not quite) the hypervisor which runs on the physical machine. And we have services that are not ‘runtimes’ but just access platforms, such as a file share solution (e.g. NFS) or the access-side of a database (Yes, this is a problematic example because an SQL query can be considered to be a program itself. I know). Some platforms mix data access and runtime, e.g. a modern RDBMS.
The idea of infrastructure, platforms and applications can be found also in the modern SaaS/PaaS/IaaS distinction that is used when discussing cloud offerings:
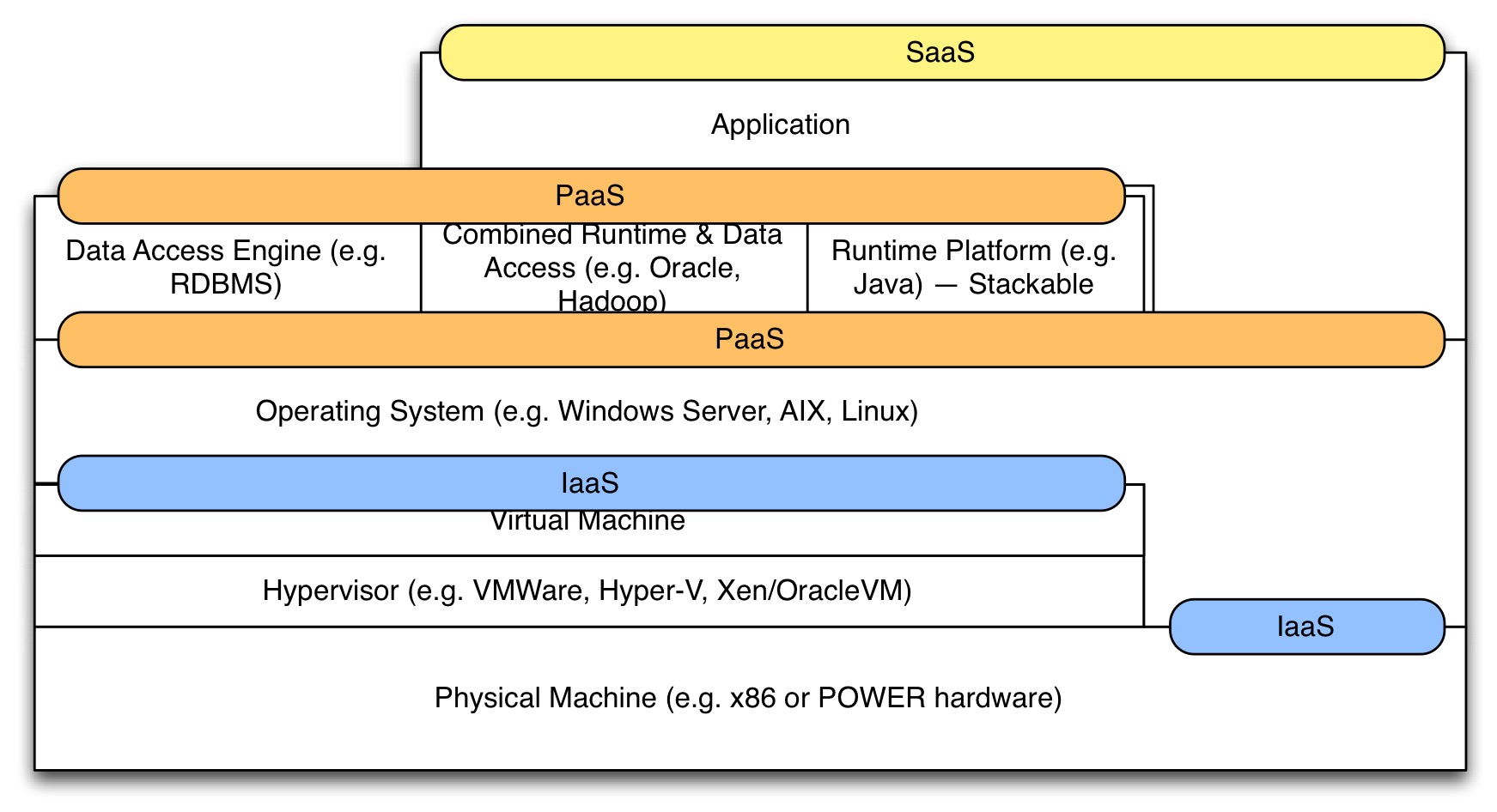 Where many “SaaS”-offerings are often some combination of SaaS and high-level Paas (e.g. an environment that also let you ‘program’ in it and thus acts as a platform for what you create yourself, such as ServiceNow).
Where many “SaaS”-offerings are often some combination of SaaS and high-level Paas (e.g. an environment that also let you ‘program’ in it and thus acts as a platform for what you create yourself, such as ServiceNow).
Anyway, here is what might be a typical approach to standardisation by an organisation:
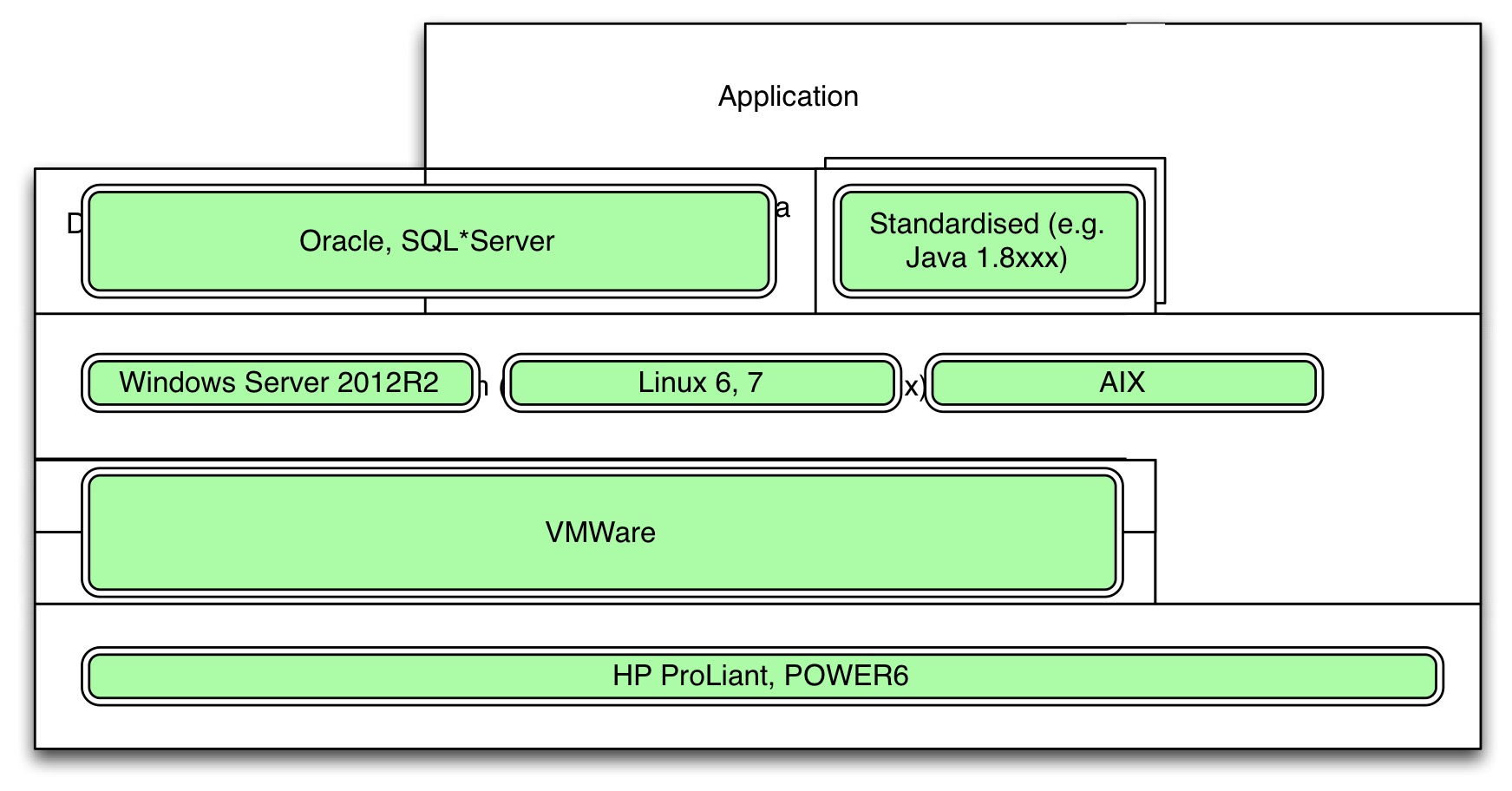
Organisations standardise the ’layers’, hence horizontally. And within a layer they try to minimise variation so as to reduce cost. Often, there is a link between how the IT-department is organised and the standards.
Now, let’s switch perspective and look at this situation from the perspective of the system providers. They don’t encounter one set of standards, they encounter many in almost every conceivable combination. Even with the market pressure towards some preferred combinations (such as x86 & Linux and POWER & AIX, even if you can undoubtedly run Linux on POWER) there are still many combinations (and versions, and combinations of versions). And to make matters worse, a single layer is not everything for a system provider. Their application may run on a certain operating system, the fact that the database runs on an operating system may be important too. E.g. if you run Oracle on AIX and your client runs Oracle on Linux you cannot be 100% certain that a problem might not come from that combination.
This situation leads to a lot of nasty limitations, puzzles, and issues for everyone concerned. The system provider cannot optimise in his stack because there are so many stacks that element-specific optimisations are out of the question. IT-departments have to fight constantly with the business to keep their landscape clean. And the Life Cycle Management conflicts of all items in the stack are a nightmare for everyone.
So, how have system providers reacted to the standardisation jungle created by their clients? Most have just tried to optimise the opposing forces of diversity and cost. But recently, more and more have reacted by turning to vertical integration. If you take a good look, you see that vertical integration is everywhere.
Take cloud-offerings. If a system provider offers a SaaS-solution, what is his big advantage? Well, the really big advantage is that he has to support only a single stack. One hypervisor, one operating system, one Java version, one database, the list is huge. And that comes with cost savings, maybe even more than the scale advantages of their data center operations. Besides, as they have a single stack, they can create stack-specific optimisations.
How many ‘cloud’ solution are there that are not elastic or scalable on-demand, but are just dedicated for the client? Actually, most SaaS-providers offer this because their clients want to be certain they get a certain performance. Yes, there is a lot of on-demand pay-per-use and elastic supply/demand, but there is also a lot of cloud that is just a packaged vertically integrated stack. Other cloud offerings also have this vertical integration property. Even the lowest level Cloud-IaaS (e.g. from Azure or Amazon) offers you a virtual machine on a hypervisor and physical hardware stack that is standardised, optimised and integrated, e.g. with special properties of the hypervisor that support the cloud-service (e.g. subtle options for throttling performance of the client).
Let’s return to the “System as VM” provider. Here is what they offer (application, runtimes/databases, operating system):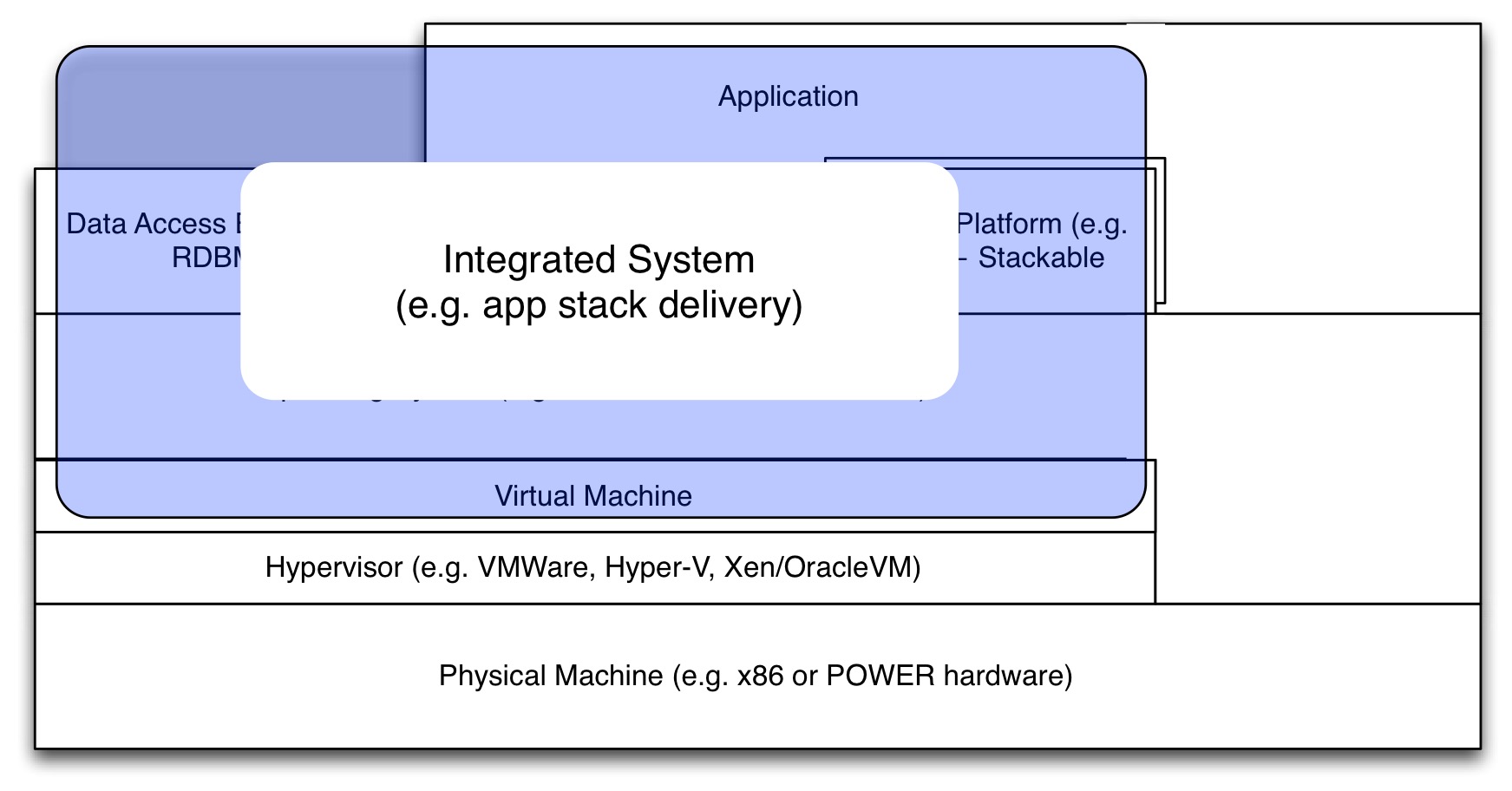 Now, almost everything in that stack conflicted with the standards set by their client. Their client supported Windows and RedHat Linux, their operating system was CentOS. Their client had standardised on Oracle and SQL*Server, their database was PostgreSQL with a bit of MySQL thrown in. The Java versions differed between what they offered and that of their clients. Their system had a completely different application server and web server stack than what was standard at their client.
Now, almost everything in that stack conflicted with the standards set by their client. Their client supported Windows and RedHat Linux, their operating system was CentOS. Their client had standardised on Oracle and SQL*Server, their database was PostgreSQL with a bit of MySQL thrown in. The Java versions differed between what they offered and that of their clients. Their system had a completely different application server and web server stack than what was standard at their client.
Here are some other examples.
The first one is a complex system that I know that comes with its own proprietary subject-specific database, but also uses MySQL for a couple of tasks, as well as a SQL*Server database for storage of other items:
 Now, this system, when it had to be deployed, led to discussions about the database standard. Interestingly, nobody complained about the proprietary database, it was seen as inevitable. But the fact that it used MySQL started a (short) discussion. After all, MySQL is a generic database, but it was not a standard database in their landscape. In the end, an exception was allowed to use MySQL.
Now, this system, when it had to be deployed, led to discussions about the database standard. Interestingly, nobody complained about the proprietary database, it was seen as inevitable. But the fact that it used MySQL started a (short) discussion. After all, MySQL is a generic database, but it was not a standard database in their landscape. In the end, an exception was allowed to use MySQL.
But the fact that the proprietary database was not discussed is telling. If the vendor had not used MySQL, but programmed its own C code (or had hidden the use of MySQL), nobody would have bothered. The term ‘MySQL’ triggered the standards-defending exception-handling processes, but this was unnecessary as the whole life cycle management of that MySQL was done by the vendor, and there was no need to set up the skills in the organisation, for instance.
Here is a fully integrated stack, something that for instance a security firm would install on your premises to support physical access controls. They install a computer, and everything on it is selected and managed by them. This is a full appliance:
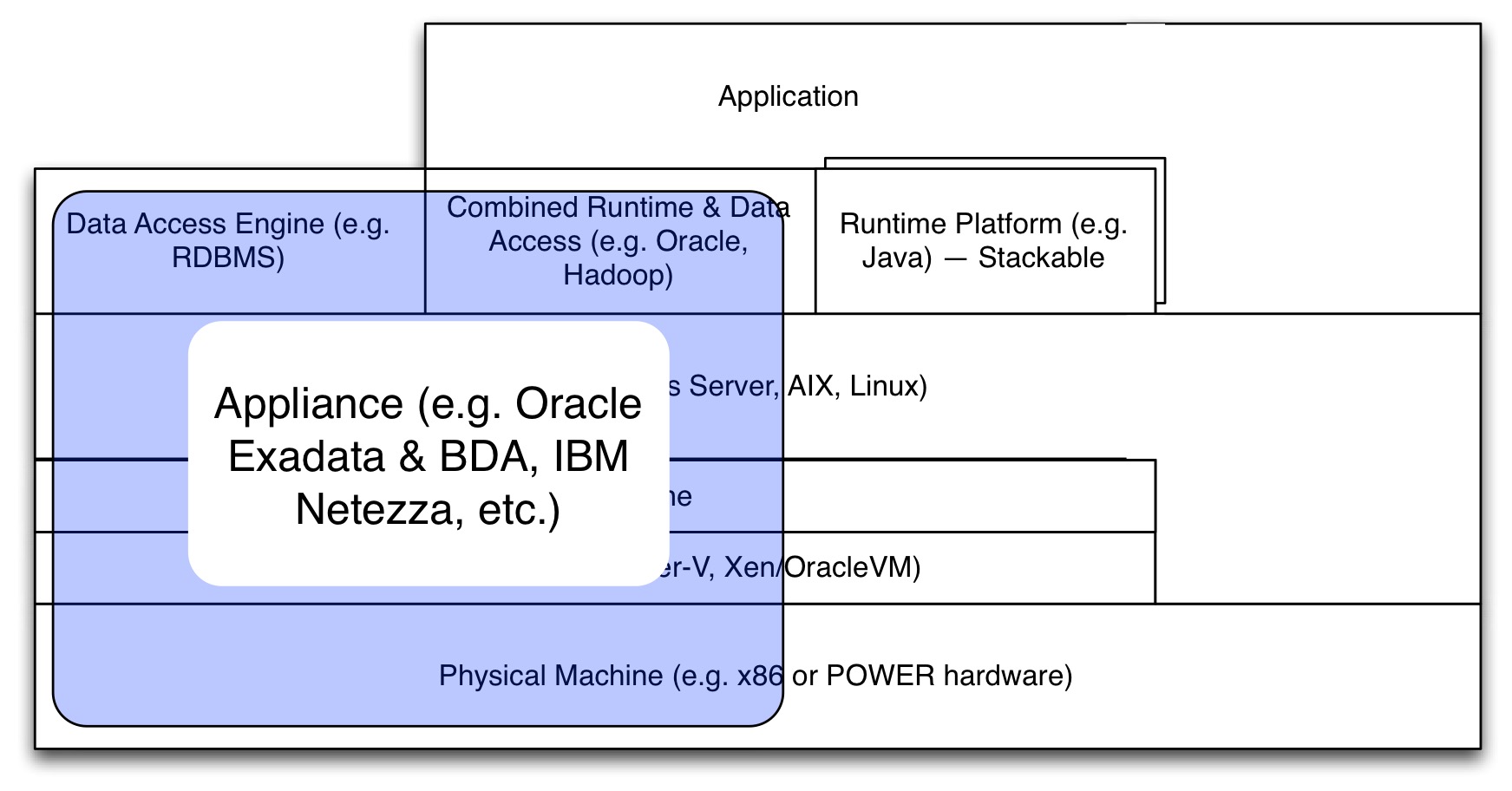
 Other appliances are shipped by some large software providers. E.g. IBM ships a fully functional analytics machine, the Netezza, and Oracle ships appliances for its database (Exadata) or for Hadoop (Big Data Appliance, actually built around the Cloudera distribution). These systems come with hardware:
Other appliances are shipped by some large software providers. E.g. IBM ships a fully functional analytics machine, the Netezza, and Oracle ships appliances for its database (Exadata) or for Hadoop (Big Data Appliance, actually built around the Cloudera distribution). These systems come with hardware:
 The Oracle example, by the way, is interesting, because they also sell the stack apart from the hardware:
The Oracle example, by the way, is interesting, because they also sell the stack apart from the hardware:
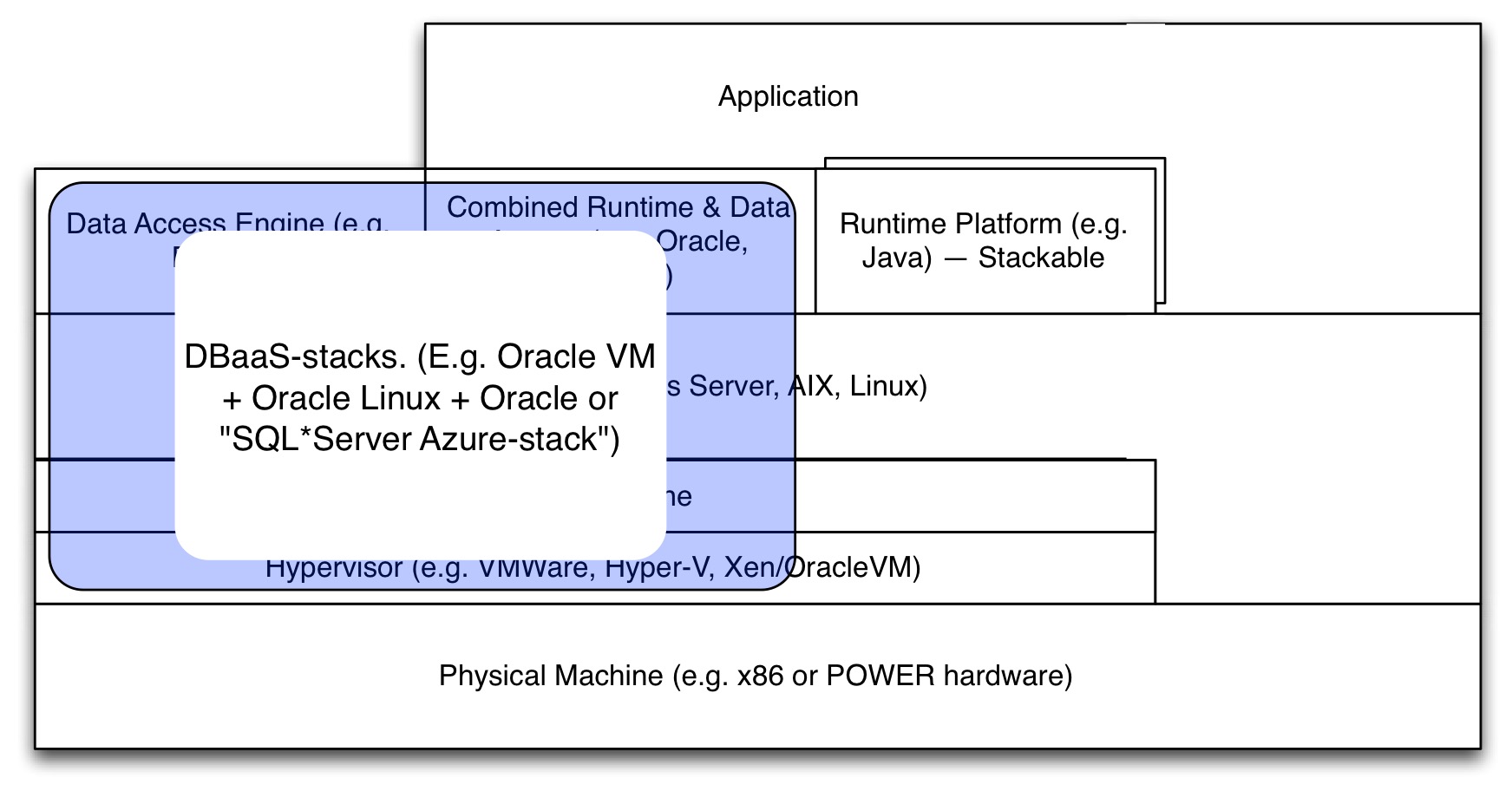 Oracle’s stack consists of their own hypervisor (which is based on the Open Source Xen hypervisor), their own Linux distribution, Java, etc. etc.. In fact, it is DBaaS-in-a-box and an example of what I have dubbed ‘reverse cloud’ elsewhere. By taking control of the stack, Oracle can optimise a lot. They may optimise their Linux especially for the demands of the database and create something that cannot run every application that should run on Linux (e.g. by messing with timing and scheduling issues in the OS), but it can run the Oracle database very well. And in the case of the Exadata, they can optimise even more, by offloading logic to the storage layer, thus minimising storage access (which is the slowest part of a database). Since data access is so often the slowest component, it pays to bring logic to where the data is.
Oracle’s stack consists of their own hypervisor (which is based on the Open Source Xen hypervisor), their own Linux distribution, Java, etc. etc.. In fact, it is DBaaS-in-a-box and an example of what I have dubbed ‘reverse cloud’ elsewhere. By taking control of the stack, Oracle can optimise a lot. They may optimise their Linux especially for the demands of the database and create something that cannot run every application that should run on Linux (e.g. by messing with timing and scheduling issues in the OS), but it can run the Oracle database very well. And in the case of the Exadata, they can optimise even more, by offloading logic to the storage layer, thus minimising storage access (which is the slowest part of a database). Since data access is so often the slowest component, it pays to bring logic to where the data is.
Now, for a company with the standards-approach shown in the third image, this breaks a lot of standards, and thus they don’t like it much. But the tide is against them. While in the 90’s of the previous century the horizontal layering and standardisation was king and everyone who championed vertical integration for a better user experience (e.g. Steve Jobs) was ridiculed, these days vertical integration is everywhere.
The question for organisations and their IT departments then becomes: how are we going to react? Well, there are a few ways they can react, but we’re in the early stages.
The first option is to move as much as possible to cloud-based SaaS and PaaS-services. IaaS doesn’t solve a lot, as it only convers a small set of items of the stack. But SaaS and PaaS come with their own issues, such as latency (see this EAPJ column, halfway down), integration, and so forth. Cloud is ideal in many ways, but it is also idealistic and the world is not always perfectly aligned with cloud solutions. Again, we’re still in early stages.
The second option is to enable yourself to handle more diversity. This means maximising the automation of your data center with tools like Puppet and so forth. This too is part of a more generic development. If there is a common theme in the last half-century of IT, then it is the observation that every time we invent technologies to simplify complexity, they tend to be used to max out complexity again to a level that is barely manageable. We might call this the law of complexity-capacity exhaustion:
Capabilities deployed to lessen the impact of complexity on the human capacity to manage the landscape result in the deployment of more complexity until the limit of the capacity of humans to manage the landscape has again been reached.
A thing like that happens here as well. After the big giants with their homogenous huge landscapes (Google, Amazon, Spotify, Ebay, Game providers, etc.) have created maximally automated elastic infrastructure operations, the medium sized landscapes are starting to be automated. But these landscapes are heterogenous, their businesses demand a plethora of various bought systems (‘canned architecture’) with a lot of diversity. Incidentally, where I work this has been coined the ‘DevOps-Ready Data Center’ or DRDC for short and ‘Enterprise Service Automation’ (ESA). An aspect of the DRDC is that infrastructure becomes fully software-defined. Infrastructure management will turn into programming (with all the complexities that brings), but this also opens up the power to manage much more diversity than has been possible until recently. Automation of the data center has been invented to cut cost and reduce complexity, but following the law stated above, we can predict it will instead be used to just support more variation and diversity. Such as supporting more variation in all layers.
And a third option is to choose vertically-integrated systems that may be on-premises, but that are managed by the system vendor. Apart from location, this almost is identical to a cloud offering. So: manage this almost just as you would manage cloud: leave the life cycle management inside the stack (the maintenance) to the vendor. Treat it like a back box, but with one exception: security. It goes too far to write that all here, but security requires more complex management. But you manage such vertically integrated solution almost as you would manage cloud solutions. Who cares about location?
Concluding: Vertical integration is an important aspect and a driver of several current developments (such as the cloud) and it is growing. It presents a problem for organisations that are all still mainly trying to fight complexity with horizontal (layered) standardisation. New technologies, such as software-defined infrastructure and cloud (either the normal kind or reverse) offer a way to manage the landscape in a different way. Organisations will probably have to redefine their standardisation policies, and possibly their structure with regard to IT operations (often set up along the same lines as standardisation), in the coming years. It will be hard for most of them to change this after so many years of fighting doggedly for the opposite.
 PS. I’ll be giving the Enterprise Architecture keynote at this year’s Enterprise Architecture Conference Europe 2016 in London UK. Subject: Chess and the Art of Enterprise Architecture. June 14, 2016. See you there?
PS. I’ll be giving the Enterprise Architecture keynote at this year’s Enterprise Architecture Conference Europe 2016 in London UK. Subject: Chess and the Art of Enterprise Architecture. June 14, 2016. See you there?






