
Many companies are enthusiastically embracing the promise — and yes, the advantages — of the public Cloud. They mainly see cost reduction and flexibility, and most see it as a way to remove complexity from their on-premise IT landscapes. Some of it might even come true.
Kidding aside, the Cloud is a natural development now that the internet transport structure has become more mature and above all virtualisation has made the large scale landscapes of the Cloud providers practical. The Cloud is no free lunch, but that doesn’t mean it is all hot air.
Today I will discuss an important limitation of use of the Public Cloud in combination with your own data center and how that can lead to a surprising development, namely the public Cloud taking residence on your premises, or `Reverse Cloud’.
I will start with a realistic example — and yes, this is IT but it is also Enterprise Architecture. You have a data center with all sorts of databases and you want to use analytics to get some useful information from that data. The analytics software needs to get its data from the database. A problem is that the analytics runs on a hardware platform that is not on your organisation’s ‘approved’ list. Adding it to your data center would be very expensive, for instance because you also need to hire appropriate skills to keep the system up and running.
Luckily, the analytics software vendor also has a ‘Cloud’ option. They host the application in their data center. Your users use it via a web browser interface. The only thing the analytics software requires is a link to the database. For this the application vendor’s data center requires a secure link to the database in your data center. Because data also lives in our data center this SaaS setup is slightly more complex than the most basic Cloud solution. Here is how it looks:
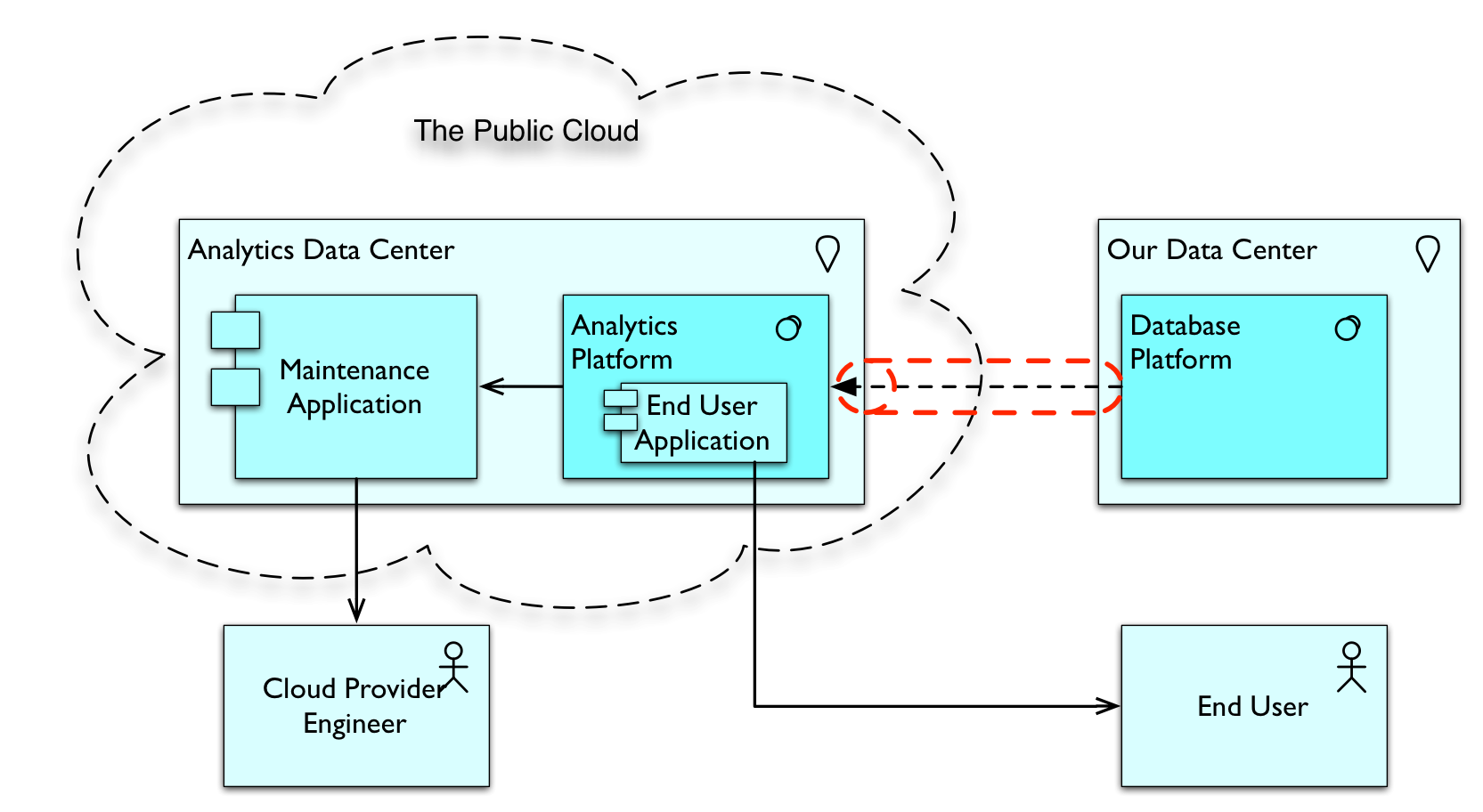
The analytics vendor has a data center from which it provides its Cloud services. Your data center has the database and a secure link (highlighted by the red tube) is set up. In the analytics platform, we find your applications, used by your end users. I’ve used ArchiMate here for the architecture drawing. The unbroken-line arrows are Used-By’s, denoting that — for instance — the DataBase Platform is used by the Analytics Platform, or that the Maintenance Application is used by the Cloud Provider’s Engineer. The dotted arrow is a Flow, which signifies that data flows from one to the other. I could have used a Used-By here as well, by the way. The red tube that denotes the secure link is not ArchiMate.
Anywhere? Not Quite.
This works without problems, except for one snag: in your particular case, the analytics program requires low-latency access to the database. For now it is enough to tell you that latency is a very hard limitation in networking and it does not help to use a bigger pipe to the internet. In fact, latency is the one factor that can make much of your bandwidth unusable. See the Aside below for a detailed non-technical explanation if you’re interested. What is important about latency is that it is a direct function of physical distance. It is the boundary to ‘anywhere’ in the phrase ‘Anything, anywhere, anytime’ that is so popular in strategy circles. For all intents and purposes, you can equate low-latency with small-distance. Anywhere? Not quite.
In other words, since our analytics platform requires low-latency, or small-distance, to your database, you have two options. One: move the database to the analytics cloud environment, and two: move the analytics to your data center.
Actually, you have a third: choose a different analytics platform that does not require low-latency access to the database, but options may be limited and there may be other adverse architectural effects. For instance, if you have business logic that creates useful combinations of different data elements and that business logic is usable in many settings, you may need in some cases have to build that logic twice in a setting where the analytics platform has its own offloaded copy of the data in its own particular ‘data base’. An operational data store or cache is also not always possible, though there are some smart options.
So, you are left with two choices. Moving your database to the analytics cloud is not a serious option in almost all cases. And that means you are left with the option of moving the analytics platform to your data center where your databases reside. Does that mean you will be incapable of reaping the advantages of the cloud solution? Today, in most cases, yes. But there is a new pattern emerging which may solve this.
Enter Converged Infrastructure…
Suppose your analytics vendor has the following interesting option: they offer to sell you a ‘converged solution’ to be installed on-premise. Converged Infrastructure is another buzzword of today behind which hides a plethora of different architectural patterns. Here it means an “Integrated Services Stack”, which means hardware and software in a ‘black box’. You do not know what is inside on storage, networking, computing, hypervisors, operating systems, etc. Those are all things you normally need to manage yourself, but you are relieved from that burden. No more patching the operating system with the latest security patch. No more managing the life cycle of the Java distribution. It might be an operating system and additional software that you do not need to have the skills for in your organisation. The vendor will patch it as part of their own maintenance cycle. The only thing you do is interact with the analytics layer.
This black box gets installed in your data center, but they manage it. In fact, they manage it exactly as they do all those boxes they offer in their own data center where they provide the cloud-based analytics solution to all their customers. It looks like this:
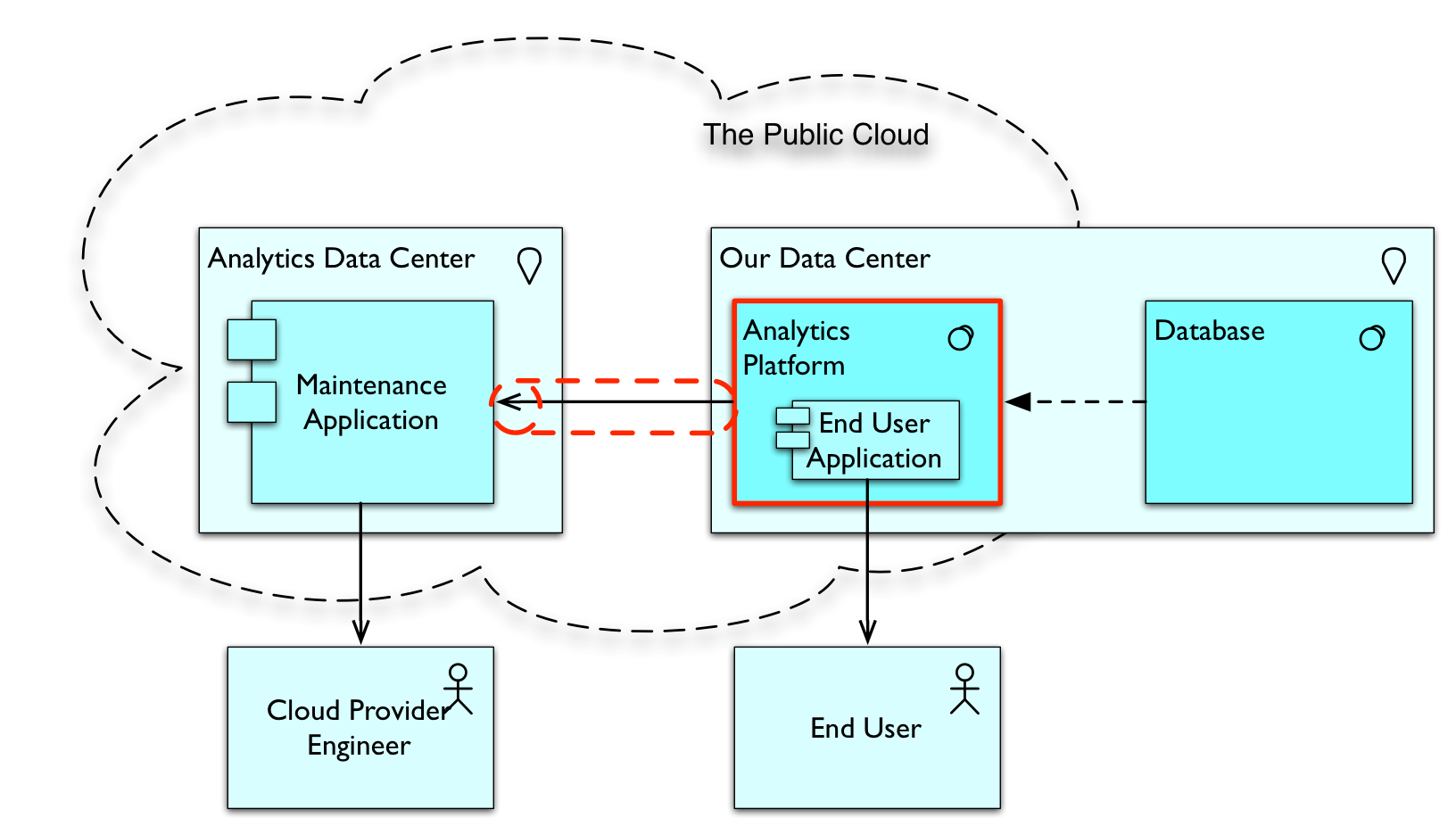
As we can see, the Analytics box is now located in your data center, but there is a secure link to their data center (the red tube) that enables them to manage the Analytics box as if it was part of their data center. Some people will say that this is not Cloud but Hosting as the hardware is not shared among multiple customers of the Cloud provider. They have a point, but consider this: if you are a customer of a Cloud solution, can you always tell the difference between dedicated and non-dedicated hardware? You can’t. And consider this: maybe we will see Cloud provisioning in multiple tiers. Tier-1: on-premise. Used by other customers of the Cloud provider as tier-3 when you are not using it. Tier-2: in the Cloud provider’s data center. Tier-3: in the data center of another customer of the data center when they are not utilising it. There is no technical barrier for these patterns at all. When the Cloud gets really mature, we might see many, many complex patterns arise and even more distribution that the current Cloud is already offering. We’ve probably seen nothing yet.
The whole clarity and simplicity of thinking about private data center versus public cloud becomes rather fuzzy here, don’t you agree? As explained in Chess and the Art of Enterprise Architecture, fuzzy and complex but real subjects like these are what Enterprise Architecture is about.
Anyway, I see a possible growth in this pattern. For instance, Oracle sells Oracle Exadata also in this manner. Instead of managing your own Oracle 12c RAC, you just put in an Oracle Exadata and the only thing left for you to do is database management. I know of several solutions such as telephony or facilities management that are already put in customers’ architectures like this. They host it in your data center. It’s not yet fully on-demand, pay-per-use as the ideal Cloud pattern gives you, but that could be a matter of time until that optimisation reaches this pattern. Of course, a purist interpretation of Cloud would exclude this, but then, it would exclude a lot of other offerings that are generally put loosely under the Cloud moniker.
When I first paid serious attention to this issue, the name ‘Reverse Cloud’ came to me. Because business-wise it is part of the provider’s landscape, the provider’s maintenance, etc. It’s just located on a different physical location and also in a different network. The secure link actually makes it more or less part of multiple networks concurrently in different ways.
The infrastructure world might become less easy to put into clear categories. Technically, I think it is ‘On-Premise Public Cloud’, a category not widely recognised yet. But I think the name ‘Reverse Cloud’ is so much more snappy. Remember: you read it here first.
The previous column can be read here: The (Forgotten) Other Half of SOA
[If you want to discuss my views with me: I will be giving the Enterprise Architecture keynote at IRM UK’s Enterprise Architecture Conference Europe 2016 on June 14 2016]The Cloud meets Albert Einstein: latency explained
Two speed limits: bandwidth and latency
If you do not know what latency and bandwidth are: here is an explanation. Both are qualities of transport. Bandwidth, sometimes called throughput’, is the name given to the amount that can be transported from source to destination per time. E.g., if you download a file at home, what matters to you is your download speed: how much time takes it to download that new movie or song (which you of course have acquired legally). People talk about bits per second (the basic speed measure) or any other form of quantity divided by time. You can compare it to how much water per second flows through a water hose. The wider the hose, the more water per second can be transported to it. The ‘wider’ your data connection, the more bits per second can be transported through it. That is why fast data connections are often called broadband. The higher the bandwidth, the better the data link.
Latency is more difficult to understand: but the water hose analogy works quite well too. Latency is the amount of time it takes water to come out of one end of the hose after you have started to pump it into the other end. If you open the tap, water comes out immediately. But if you attach a 20 meter water hose, it takes some time before the water that has entered the hose at the tap end reaches the other end. That delay is called latency. In data connections, exactly the same happens. There is a delay before the data that is sent at one end reaches the other end. The lower the latency, the better the data link.
Now, bandwidth is in a practical sense unlimited. We’re far, far from reaching any practical limit in the width of our data hoses. But latency has an absolute lower boundary which is directly related to the distance between both ends of the data link. Data travels roughly at the speed of light, which is a hard boundary in physics. You cannot go faster and still carry information. So, if you have a 300km (200mi) distance between the two endpoints of a link, you will have at least a latency of 1 millisecond, because electricity, like light, speeds at roughly 300,000 km/s.
Adding 1 millisecond to a download of minutes doesn’t sound like a real problem, but it can kill you, because latency can affect bandwidth.
How latency can affect effective bandwidth
Suppose you have two systems exchanging data and each has to wait for a reply when something has been sent. As this is built into the lowest of our network systems to provide reliability of communication (sent data is being acknowledged by the receiver or the sender will send again) this almost always happens. So, how much data can be effectively sent (bandwidth) on a 1 Gbit/second (1 billion bits per second) physical link? This translates to roughly 100kB/s (hundred thousand bytes per second). But not quite. Because the data is sent in chunks (packets) of maybe 1.5kByte (1500 Bytes). So this happens:
- A starts sending 1500 Bytes to B over a distance of 300km (200mi)
- 1msec later B starts receiving it and immediately starts working with it, 0.012 msec later the last bits have arrived.
- Now, B sends the acknowledge to A. This is only a few bytes, so the time to get it into or out from our data hose it is negligible. Like how much time it takes to push a few drops into a water hose. But it still takes 1ms for the data to arrive at A after B has started sending it.
- Now, A can send the next 1500 Bytes.
In other words, in this scenario, sending 1500 bytes takes 2ms. That translates to 750,000 bits per second, which is more than 1000 times as slow as our bandwidth of 1,000,000,000 bits per second would suggest. Your 100 kB/s has gone down to 0.1 kB/s. It is as if, instead of using a hose, fill cups with water at the tap, throw this to the other end, wait for a drop to return and then throw the next cupful. Most of the time is spent in waiting.
The numbers above are not completely realistic but serve as an illustration. In reality networks have a lot of smart techniques to minimise this effect, mostly based on not waiting for an acknowledge on each packet before sending a new one (keep the data hose filled) and just keep track of which packets have been acknowledged and which haven’t and resending these. But latency never goes completely away. Especially, because most latency comes not from the physical speed of transport, but from all the hops in between, because a distance of 300km cannot be done with a single stretch of cable with a high bandwidth. All the intermediate devices that are needed to span the distance add milliseconds and not microseconds to the delay. In reality, a 300km distance link may come with 7ms latency, of which only 1ms comes from the speed of light limit.
Computing over large distances may seriously degrade performance in cases that are sensitive to latency. Mostly this happens if data is sent in small chunks so the network cannot keep the data hose filled to the brink.
Which reminds me of a funny quote from Andrew Tanenbaum of Computer Networks fame. “Never underestimate the bandwidth of a station wagon full of tapes hurtling down the highway”. Nope. But the latency…







2 Comments