 Many organisations are now combining a modern web-presence, with individual clients directly interfacing via web sites or apps in self-service (though it might be better to drop that concept, architecturally), and large administrative systems running the large operations often required, often working also with massive batches, such as payments at the start of end of a month. Many organisations have been moving (at least partly) to Service-Oriented Architectures (SOA), one of the most influential architectural patterns today, by some still seen as the panacea for all architectural problems, the silver bullet that allows us to manage all the complexities.
Many organisations are now combining a modern web-presence, with individual clients directly interfacing via web sites or apps in self-service (though it might be better to drop that concept, architecturally), and large administrative systems running the large operations often required, often working also with massive batches, such as payments at the start of end of a month. Many organisations have been moving (at least partly) to Service-Oriented Architectures (SOA), one of the most influential architectural patterns today, by some still seen as the panacea for all architectural problems, the silver bullet that allows us to manage all the complexities.
There have been many `silver bullets’ in the short history of enterprise architecture, and — as Frederick P. Brooks so beautifully wrote around 1987 — none of them actually were silver bullets. No single technological advance or management technique has solved the problems of complexity and unpredictability that are the focus of enterprise architects. That does not mean that all those advances were meaningless. Agile/Scrum does improve running certain types of projects. Functional decomposition of organisations (thinking in `business functions’) does create some clarity in the mess of interactions within organisations. Object-Orientation has enabled us to create far more complex programs than procedural programming did before. Service Oriented Architecture has enabled us to create far more complex landscapes, though it does lead to `loosely coupled spaghetti‘ and other problems (one of which is a subject of this column).
Each of these advances has some neat foundational idea or insight at its core, an idea that has merit and that fuels high hopes for a silver bullet. Architects love such ideas/insights, they are people who are often exceptionally good at patterns, models, abstractions. The basically decent idea of service oriented architectures has for instance led to a movement of multi-layered architectures, consisting of presentation-layer, application-layer, integration-layer, database-layer, etc. etc.
I’ve seen such models, lovingly created by architects who above all strive for structure and clarity. To quote Terry Eagleton (see column introduction on the right): “It was beautiful! A world purged of imperfection and indeterminacy. Countless acres of gleaming ice stretching to the horizon.”
Alas, such models also are no silver bullets. In fact, I’ve seen various projects get into serious trouble because of them. The main reasons are threefold: brittleness (see the aforementioned loosely coupled spaghetti link for an example), maintainability and performance. This column is going to address the last one of these, in order to present a pattern that is often overlooked, if not forgotten by strict-SOA-adepts.
A Story of Bottlenecks
At one time, a health insurance company had become enamoured by its beautiful layered IT-architecture, titled the `application structure standard’. They had created a design/architecture standard that told their developers to separate presentation layer from application layer (layered), to have data owned by one business function and served to others (silo), to keep data in one ‘master’ application (single source of truth) to prevent multiple confusing values in different systems, and use services (SOA) to connect these via an Enterprise Service Bus (ESB) so the business functions were loosely coupled. And they ordered flexible solutions that would be easy to adapt to different policy types and different clients. So, the standard said to make use of business rule engines (BRE) for the implementation of these.
Now, this health insurance company sold to employers, who provided this to their employees. And, being a successful insurer, they had lots and lots of clients. An insurer needs to receive the data (who is covered, who not, etc.) and the premiums from the employer. The system supporting the administration of premiums was old and needed to be retired. Given the unique nature of their setting, they had to build their own, they were unable to source this from a vendor.
This Receive-Insurance-Premium system (in short: RIP) would receive information provided by the employer in a file, match this with the policy records of each insured employee using the BRE, and add a ‘money to be received’ entry in their accounting system. This was implemented as follows: for every record in the received file, go to the Insurance-Member-Policy system (IMP) that is being run by another business function, get the policy data, then check (using BRE rules) if the employer will pay the correct premium for this employee. When finished, add the totals in the accounting system as a ‘receivable’, while sending the employer a message containing the problem cases and ask them to update their records and make an additional payment (or receive an additional payback).
The system was built according to all the specifications, including the strictly layered and siloed ‘application structure standard’ (or ASS, for short) from the enterprise architecture function. And then it was put to the test and it turned out that there was a massive performance problem. Because these employers all send their files about the previous month in during the first 2-3 days of the new month. So, the system was confronted with millions of records, one for each employee of each employer. For every single record, a roundtrip had to be made from the RIP system via the ESB to the IMP system. The IMP system took some time finding the data too. In the end, the architecture was such that the performance was totally unacceptable. Bandwidth was not a problem, but the latency of all these steps turned out to be killing. And the question was: how do we fix this performance problem of the RIP system that is the result of our SOA architecture?
Before we go on, the problem was of course the architecture guidelines provided by the enterprise architecture function. Such a pattern as they had provided scores very well on a single use case: a web front end getting individual member’s data and working with that, the paradigm of the day.
If you look at these patterns in general, you can look at their effect on three aspects of operations:
- Throughput: how much data can go through per time unit (how wide is the pipe)?
- Latency: how quickly will the answer start returning (how short is the pipe)?
- Flexibility: how easily can we support different uses (how bendy is the pipe)?
The pattern behind ASS was very good from a couple of perspectives: the decoupling made it flexible: this is a general requirement from enterprise architecture, because the health insurance provider is multi-client and multi-policy. It had acceptable latency for something like and individual member’s web page and the throughput for such individual requests was not a problem either.
Back to our story: how do we solve the performance problem? Should we employ a cache?
What is a cache?
When your browser requests a page from a web server, you get a page. The page is generally a file that has been created in HTML(5), CSS(3) and Javascript. Now, close your browser, open it again and type the same URL. Without a special mechanism, that would mean downloading everything again that was just downloaded. When the internet started booming, during the 90’s, download speeds were extremely slow compared to today. A fast modem was able to download 33k6bps, or 33,600 bits per second, whereas these days, homes may be connected at speeds up to 100Mbps, or 100,000,000 bits per second, or 3000 times the speed of half way the 90’s. Pages were smaller too, but not by that much.
So, soon, the web browsers started to use a cache. The word cache comes from French and it means something like ‘hidden storage’. Instead of getting the page every time through the slow internet, the browser first looks if it is already available in the local cache, if not gets it (and stores it in the cache) and uses the local copy. Only the first time you download a page is slow, every next time is very fast because it comes from your local disk. This pattern is still in use; my browser currently has a cache of ±500MB. Let’s enliven this post a bit with a small ArchiMate picture about the details of what happens (ArchiMate is a leading enterprise architecture modelling language, more below):
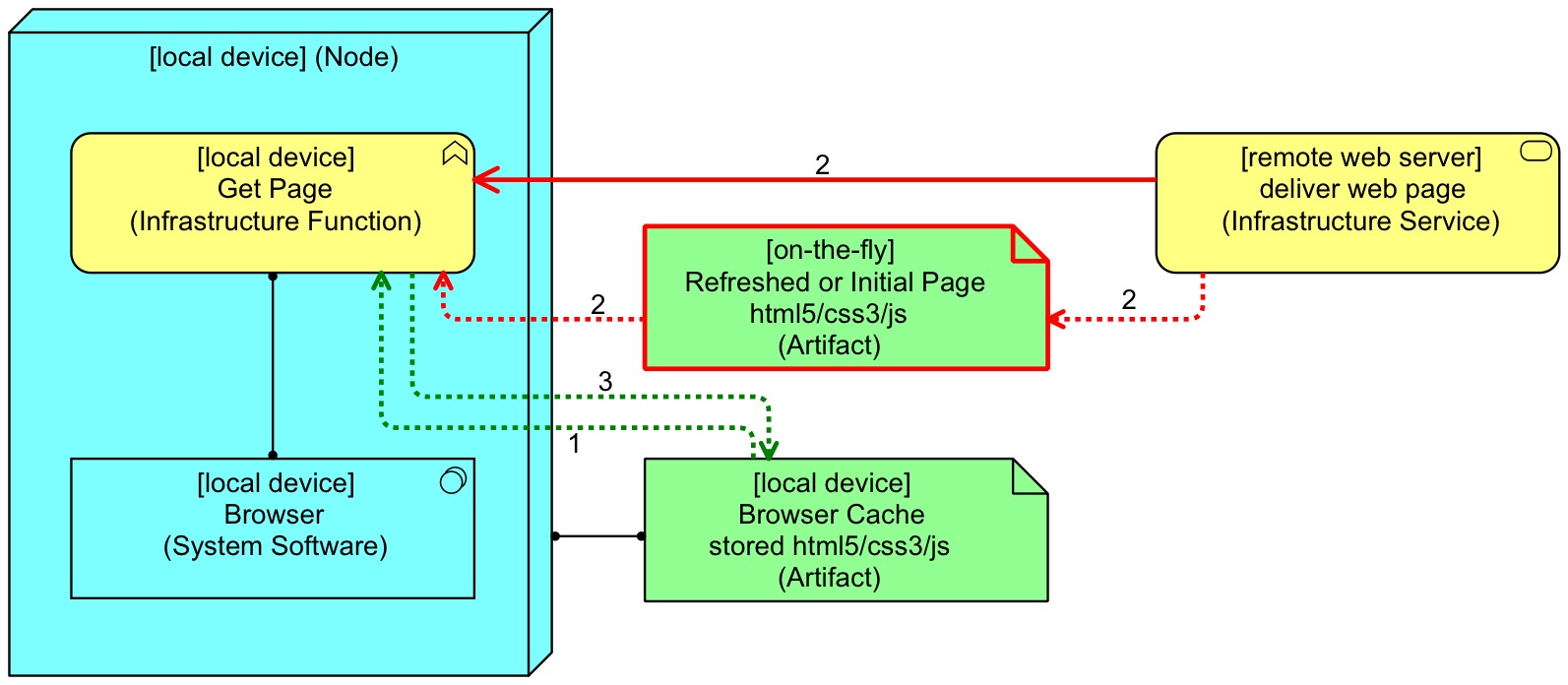
The picture shows a ‘local device’ (e.g. a PC or iPad) on which a browser runs. The open red arrow is an ArchiMate Used-By relation, it shows that the browser functionality uses the web server. The dotted open arrows are ArchiMate Access relations. They show read and write access from behaviour to passive data. If you request a page, the browser’s behaviour is to first look in the cache (1), and if not found or outdated, request the page from the web server (2). If it is received, it is also written (3) to the cache. The fast relations are coloured green, above, (local read/write) the red ones (requesting the page from the web server) are slow. ArchiMate is scale-independent, you can as easily model both high level and detailed architecture with it. You can read more about ArchiMate and find a free PDF syntax primer download — and a decent book on the language 😉 — on the Mastering ArchiMate web site.
Of course, the problem with a cache is that its data gets outdated. If the web site is updated on the web server end, how does the browser know if it needs to download the updated copy? For that, web servers add some data to the returned page, data that contains information about how long the returned data may be considered valid. Additionally, if you do a reload of a page in your browser, the browser is forced to get a new copy. That is why you still sometimes see that tip mentioned: in case of trouble, try reloading the page. This prevents you from working with an outdated copy.
Caches are a common way to address performance, they are everywhere in computing. You don’t see them, that is why they are called caches after all. Sometimes, in Business-IT landscapes you find huge versions of a cache, called an Operational Data Store. These often lack the update-intelligence that web browsers and servers have, often they are fixed at a regular interval, say daily. As a result, the system using the cached information is fast, but it also may work with data that is out of date. This is why many architects prefer direct SOA couplings, straight-through processing (STP) and such, they are the best patterns to prevent wrong data, and that requirement is always very high on an architect’s wish list.
The ‘Forgotten Half’ of Service Oriented Architecture
Back to RIP, ASS and IMP. Originally, according to ASS, the following SOA-setup was implemented (ArchiMate, again):
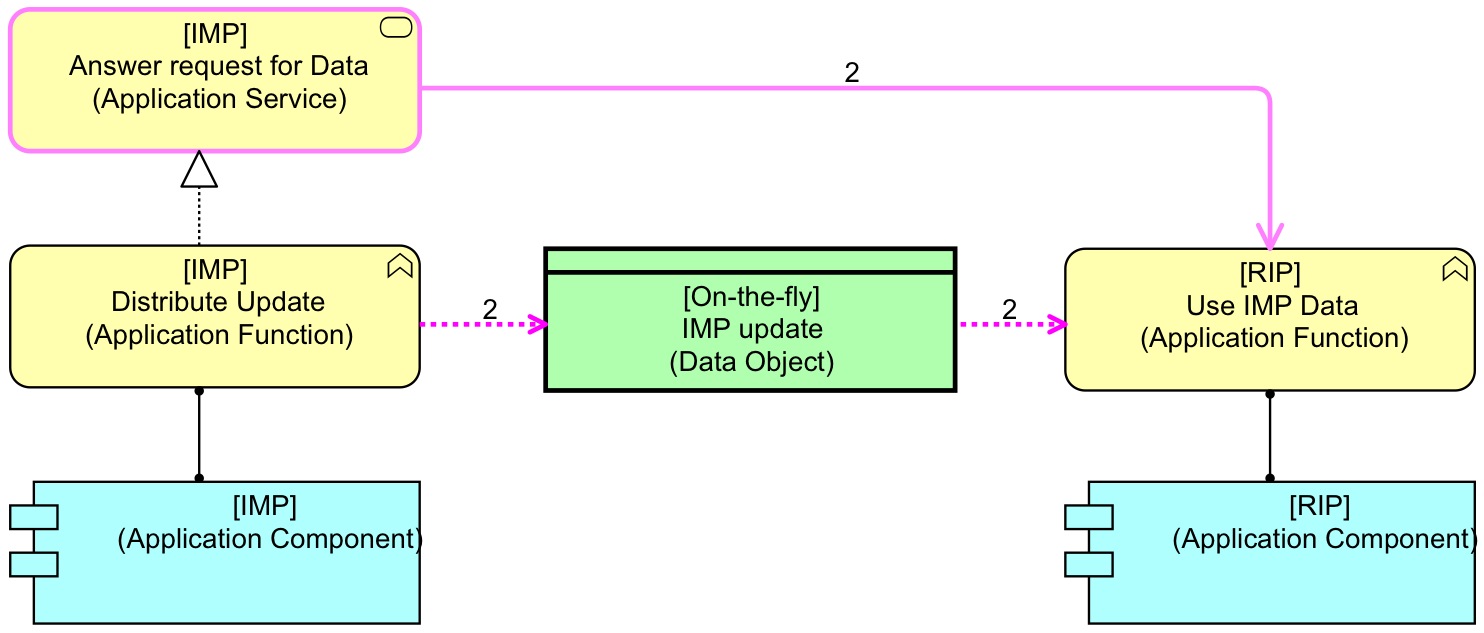
We leave out the whole ESB complexity from now on. The underlying assumption is that either because IMP itself is slow or the communication between RIP and IMP is slow (latency, bandwidth, whatever) the performance of RIP directly calling IMP becomes problematic when it is done massively. In that case, most of RIP’s time gets lost in waiting for the reply from IMP.
Ignore the labels ‘2’ for now. What we see here is that IMP provides a service that is used by RIP to get policy data. But, in our real situation, the performance of this was hopeless. A standard cache solution for the SOA setup could look like this:
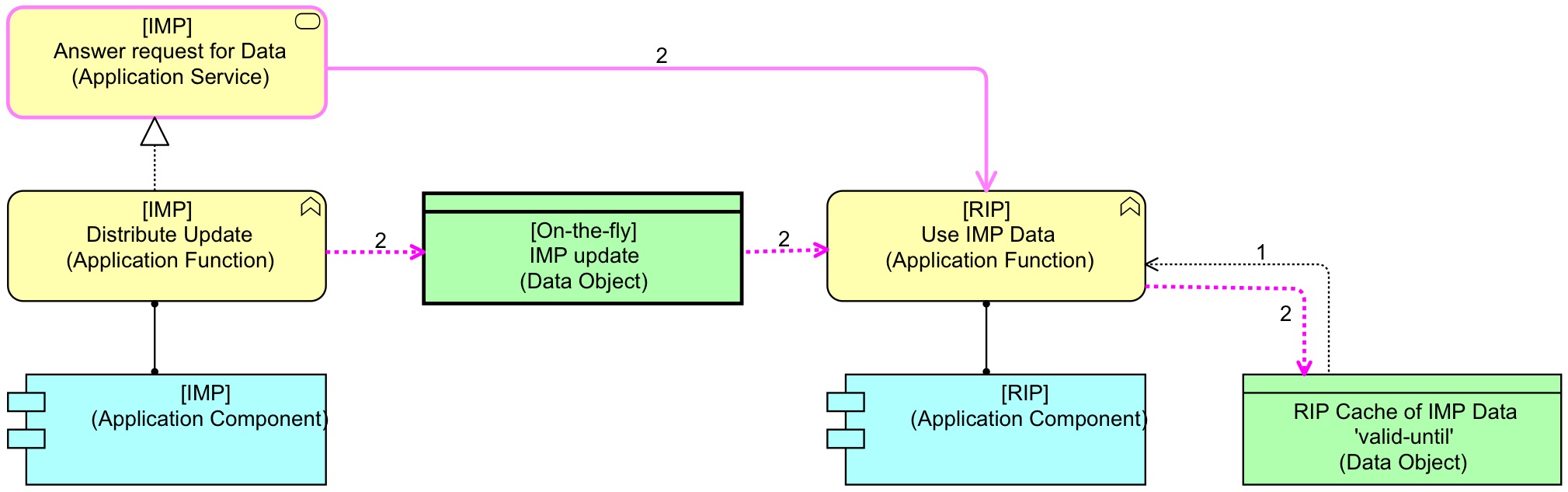
What you see here is the standard classic SOA with a client-maintained cache. If RIP needs IMP data, it first looks in the cache (1). If there is data in the cache that is not marked out-of-date. If the data needs to be refreshed, RIP uses the service from IMP and receives the data (all 2 relations are concurrent). The problem is that we might be using data that is out of date.
Given that we cannot accept that we work with invalid data, a cache is out, right? Wrong. But we need a bit of a different cache that the standard pattern that is part of the browser/webserver setup. We need a cache that is by definition up-to-date. There is in our landscape only one system that can guarantee that: IMP. Instead of RIP caching data it requests from IMP, we need IMP to write RIP’s cache, and RIP to read that cache. And to prevent hard links in our landscape (bad for flexibility, but sometimes just the best pragmatic option) we make use of the ESB’s publish-subscribe mechanism. IMP publishes changes on the ESB and RIP subscribes to them, storing them locally and using them as needed.
This ‘server-updated cache’ pattern looks like this:
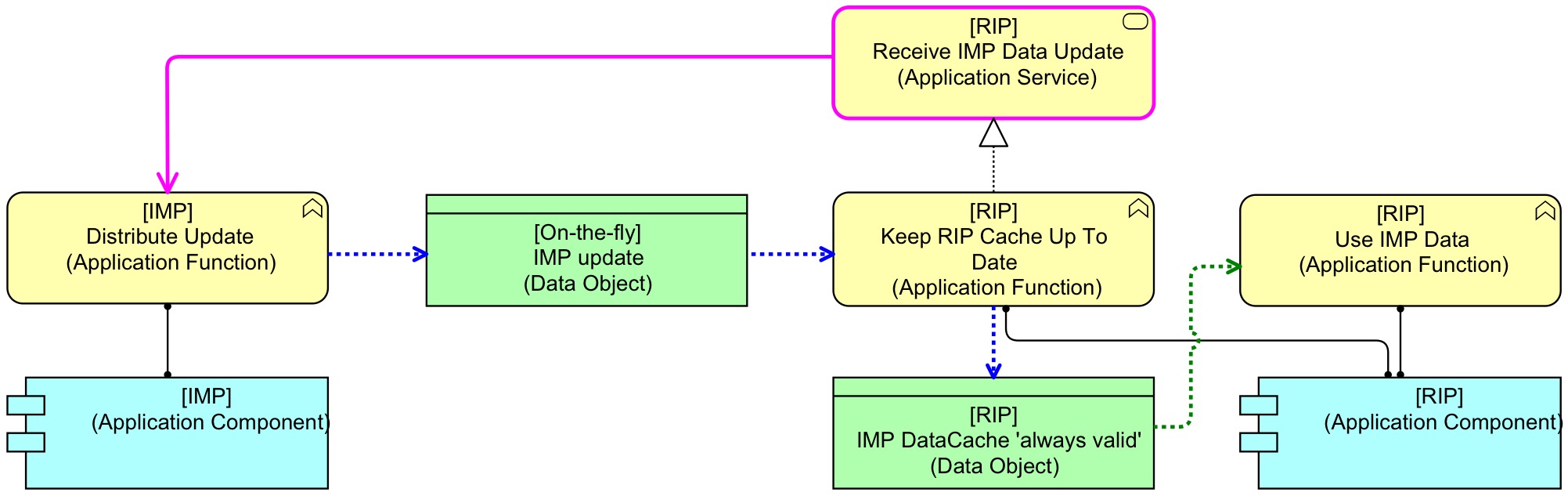
However we do it — directly or via the ESB — instead of RIP using a service from IMP, in effect we need IMP to use a service from RIP. Every time IMP updates data, it uses a service from RIP (pink) and sends it the updated data. That functionality from RIP immediately stores it in the cache. The filling of the cache is shown by the blue relations. RIP uses only the local cache which is always up to date, as it is updated by IMP itself. In an abstract sense, IMP `controls’ RIP’s cache. We might call this pattern server-updated cache.
A variation of the pattern would be that a third application manages the cache which makes it available to RIP. RIP could even come with that third application itself: RIP Agents that run on the environments where a cache must be maintained:
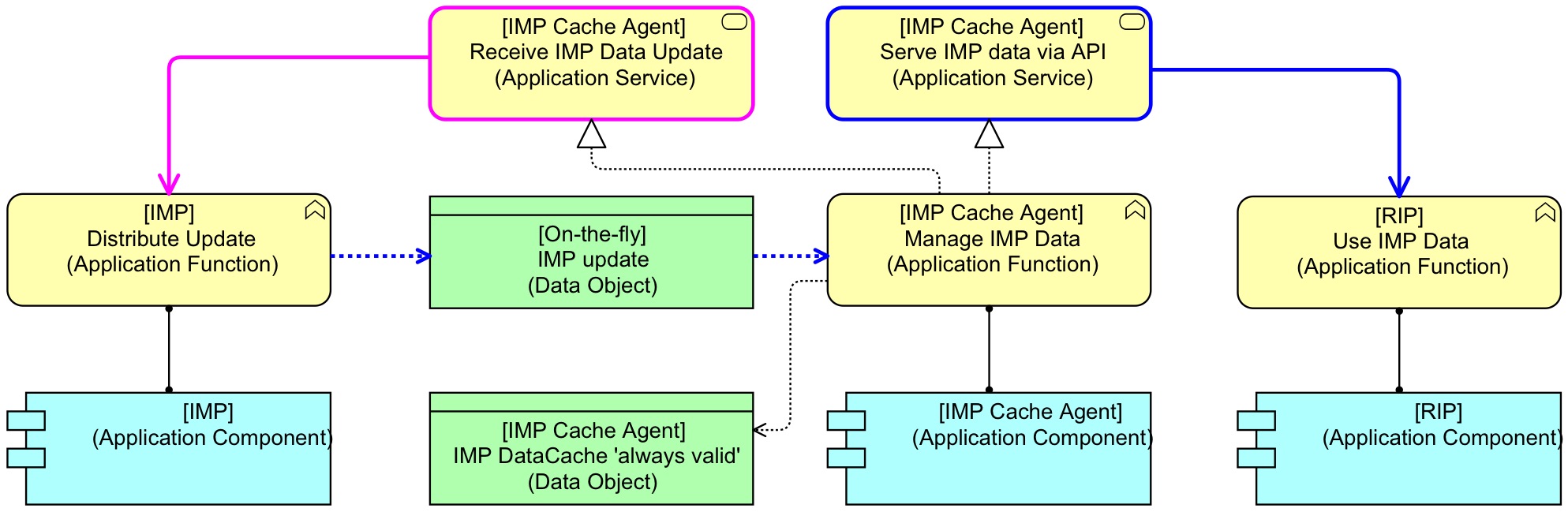
This way, RIP doesn’t have to maintain its own ‘always valid’ cache, but IMP maintains a cache on RIP’s environment that RIP can use locally (and thus fast). In fact, the local IMP Cache Agent acts as a fast local proxy for IMP in a back-to-back SOA setup. (Of course, the IMP Cache Agent itself must be pretty fast or it would not solve the performance problem. In a worst case, we might let the cache agent write directly in a database that RIP can use.) We might call this pattern ‘server-owned cache’.
Application SOA versus Business SOA
While in business terms, the receive-premiums function uses the policy-administration function, technically we want the policy-administration application to use the receive-premiums system application. The RIP system must provide a service for the IMP system to send it data. This is the often forgotten half of SOA: you do not only offer services to provide data, sometimes you must provide services to receive it. In a small ArchiMate picture:
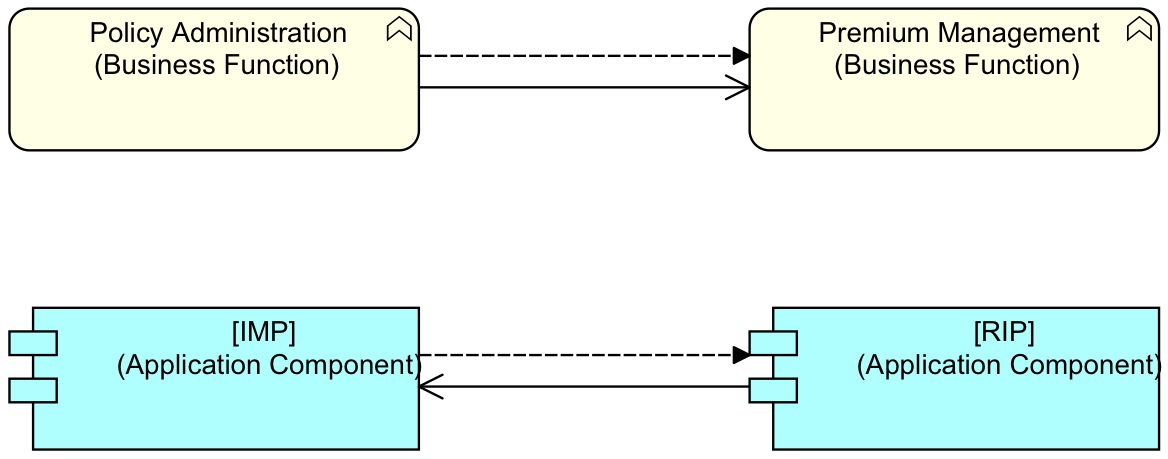
Again, for those unfamiliar with ArchiMate: the line arrows with open head are Used-By relations, these run from the used to the user (the reason for this direction is outside the scope of this column). The dashed arrows with closed heads are ArchiMate Flow relations, which are shortcuts for saying information or data flows form one to another somehow. While the flow goes in the same direction, the structural relation has the opposite direction, showing that as far as application-SOA is concerned, its is IMP that uses RIP, in other words, it must be server-updated or server-owned.
Note: some ArchiMate practitioners will want to model the structural relation (Used-By) at the application layer in the same direction as the one shown in the business layer above, but though that interpretation is of course allowed (ArchiMate is not specific at that point) I think it is an abstraction that makes everything less clear; it also sort of mixes the Flow with the Used-By. But that is of course a matter of taste and ArchiMate is not prescribing either form.
The next column can be found here: Reverse Cloud
The previous column can be found here: Are you an Architect? Really?
[Update 16/Feb/2015: Removed the short phrase about the relation between SOA and OO design patterns as it was neither important, nor very strong] [If you want to discuss my views with me: I will be speaking at the Gartner EA Summit 2015 London UK on May 20 2015 and the MBT-Congress in Houten NL (closing keynote) on May 21 2015]






2 Comments